Internet 5G
Wprowadzenie
Ewolucja technologii internetowych zbliŋyģa się do caģej usģugi przeģączania pakietów IP, która uksztaģtowaģa sposób, w jaki ŋyjemy, pracujemy, uczymy się i bawimy. Dzisiejszy Internet zapewnia bogatą paletę usģug, które obejmują między innymi rozrywkę medialną (np. gry audio, wideo i gry wysokiej rozdzielczoķci), personalizację (np. Haptics, aplikacje oparte na obecnoķci i usģugi oparte na lokalizacji) i bardziej wraŋliwe oraz aplikacje krytyczne dla bezpieczeņstwa (np. e-handel, e-Zdrowie, osoby udzielające pierwszej pomocy itp.). Wedģug statystyk Międzynarodowego Związku Telekomunikacyjnego (ITU), globalny Internet zostaģ osiągnięty przez ponad 2,4 miliarda uŋytkowników na caģym ķwiecie w czerwcu 2012 r., A liczba ta stale roķnie. Badanie firmy Ericsson przewiduje 40-krotny wzrost ruchu danych z telefonów komórkowych i przenoķnych komputerów osobistych / tabletów w latach 2010-2015 . Ponadto prognoza Cisco dotycząca wykorzystania sieci IP do 2017 r. Ujawniģa, ŋe ruch internetowy ewoluuje od bardziej stabilnego do bardziej dynamicznego. Globalny ruch IP będzie odpowiadaģ 41 milionom pģyt DVD na godzinę w 2017 r., A komunikacja wideo będzie nadal w zakresie 80-90% caģkowitego ruchu IP. W tym kontekķcie niemal kaŋdy obiekt fizyczny, który widzimy (np. Ubrania, samochody, pociągi itp.), Równieŋ zostanie podģączony do koņca dekady, tworząc Internet przedmiotów (IoT). Przykģadem jest komunikacja Machine-to-Machine (M2M) wykorzystująca sieci oparte na czujnikach, co skutkuje dodatkowym czynnikiem napędzającym wzrost ruchu. Okazuje się, ŋe sterownikami przyszģego Internetu są wszelkiego rodzaju usģugi i aplikacje, od niskich przepustowoķci (np. Danych czujnika i IoT) do wyŋszych (np. Strumieniowanie wideo w wysokiej rozdzielczoķci), które muszą byæ kompatybilne, aby obsģugiwaæ róŋne opóžnienia i urządzenia. Na przykģad aplikacje oice over IP (VoIP) wymagają co najwyŋej 150ms opóžnienia, 30ms jitteru i nie więcej niŋ 1% utraty pakietów, aby utrzymaæ optymalną jakoķæ postrzeganą przez uŋytkownika (QoE). Interaktywne strumienie wideo lub wideokonferencje, osadzają poģączenia gģosowe, a tym samym mają takie same wymagania dotyczące poziomu usģug jak VoIP. Natomiast usģugi przesyģania strumieniowego wideo, znane równieŋ jako wideo na ŋądanie, mają mniej rygorystyczne wymagania niŋ VoIP ze względu na techniki buforowania zwykle wbudowane w aplikacje. Inne usģugi, takie jak FTP (File Transfer Protocol) i e-mail, są względnie nieinteraktywne i niewraŋliwe. Jednak protokoģy kontroli sieci i zarządzania wymagają odpowiedniej gwarancji przepustowoķci, aby zapewniæ, ŋe komunikaty sterujące są prawidģowo dostarczane na czas, aby zapobiec pogorszeniu wydajnoķci. Co więcej, dotychczasowy Internet traktuje usģugi jednakowo na zasadzie najlepszych staraņ. Ponadto sieci obecnych operatorów są wypeģnione duŋą i rosnącą róŋnorodnoķcią zastrzeŋonych urządzeņ sprzętowych. Z tego powodu uruchomienie nowej usģugi sieciowej często wymaga znalezienia odpowiedniej przestrzeni i mocy, aby pomieķciæ nowe skrzynki. Osiągnięcie tego celu jest niezwykle trudne i nadąŋaj za nowymi trendami, poniewaŋ innowacje technologiczne i serwisowe przyspieszają i skracają cykl ŋycia sprzętu. Ponadto infrastruktury sieciowe wymagają zautomatyzowanych moŋliwoķci kontroli skalowalnoķci, niezawodnoķci i dostępnoķci, szczególnie w duŋych ķrodowiskach sieciowych, w celu zmniejszenia wpģywu ręcznej interwencji, która staje się kosztownym towarem. Inne obawy obejmują rosnące koszty energii, wyzwania związane z inwestycjami kapitaģowymi oraz problemy narzucone przez projektowanie, integrację i dziaģanie coraz bardziej zģoŋonych urządzeņ sprzętowych. Te rosnące ograniczenia Internetu w zakresie zarządzania siecią, które jest trudne do wdroŋenia, oraz przekazywania najlepszych wyników, które nie speģniģy wymagaņ jakoķci usģug (QoS) dla aplikacji o wartoķci dodanej, są dobrze znane w spoģecznoķci badawczej, czy to w ķrodowisku akademickim, czy w przemyķle. Dlatego powszechnie przyjmuje się, ŋe architektura internetowa musi zostaæ poddana renowacji, a wiele propozycji, w tym podejķcie "czystego ģupka", zostaģo zaproponowanych. Jest coraz bardziej oczywiste, ŋe w sieciach komunikacyjnych zbliŋa się punkt zwrotny dzięki stopniowemu wprowadzaniu sieci definiowanych programowo (SDN) i wirtualizacji funkcji sieciowych, aby zapewniæ wymaganą elastycznoķæ i reaktywnoķæ. W szczególnoķci SDN sugeruje, ŋe odsprzęgnięcie pģaszczyzny sterowania siecią od pģaszczyzny danych (np. w chmurze) i wirtualizacja sieci pozwala na tworzenie wielu róŋnych logicznych funkcji sieciowych na jednej wspólnej wspólnej infrastrukturze sieciowej. W literaturze OpenFlow i GENI próbują zachęciæ dostawców sieci do programowalnych przeģączników i routerów (np. Wykorzystujących koncepcje wirtualizacji i SDN), które mogą przetwarzaæ pakiety dla wielu izolowanych sieci eksperymentalnych jednoczeķnie.
Co więcej, ostatnie wyniki badaņ dowodzą, ŋe nadmierne dostarczanie zasobów sieciowych, polegające na rezerwowaniu większej iloķci zasobów niŋ moŋe wymagaæ Klasa usģug (CoS), moŋe skutecznie osiągnąæ róŋnicowanie QoS w sposób skalowalny, którego podejķcie jest fundamentalne dla przyszģego Internetu. Podczas gdy technologie te (tj. SDN, wirtualizacja i nadmierne udostępnianie QoS) obiecują poprawiæ wydajnoķæ sieci w przyszģoķci, wciąŋ są w powijakach, a dalsze analizy i badania nadal są uwaŋane za konieczne. Na przykģad nadmiar zasobów naleŋy starannie zaprojektowaæ, aby zapobiec marnotrawstwu zasobów. Aspekty te są dodatkowo napędzane przez rosnące uzaleŋnienie od Cloud Computing, gdzie róŋne modele, takie jak Software-as-a-Service (SaaS), Platform-as-a-Service (PaaS) i Infrastructure-as-a-Service (IaaS) oraz inne aspekty operacji sieciowych i usģug są wirtualnie hostowane przez Internet. W szczególnoķci SaaS jest modelem usģug w chmurze do dostarczania oprogramowania, w którym oprogramowanie i odpowiednie dane są przechowywane w chmurze, a dostęp moŋna wykonaæ za pomocą prostej nawigacji w przeglądarce internetowej (np. Google Mail i Google Docs). Ponadto model PaaS umoŋliwia ķwiadczenie usģug niŋszego poziomu, takich jak system operacyjny, serwer WWW lub tģumacz języka komputerowego jako usģugi. Wykorzystując na przykģad PaaS, programiķci mogą tworzyæ wģasne aplikacje bez koniecznoķci instalowania cięŋkiego oprogramowania na wģasnych komputerach (np. Google App Engine). Ponadto model IaaS zapewnia infrastrukturę sieciową, w tym serwery w centrach danych (DC), z których klienci chmury mogą korzystaæ na zasadzie pay-to-you-go (np. Amazon Elastic Compute Cloud). W związku z tym, poniewaŋ wirtualizacja umoŋliwia emulację sprzętu komputerowego w oprogramowaniu, a kilka emulowanych komputerów (wirtualnych komputerów) moŋe dziaģaæ jednoczeķnie na jednym fizycznym komputerze, caģa infrastruktura i transport sieciowy mogą byæ efektywnie udostępniane jako usģuga, wzmacniając róŋne scenariusze, począwszy od sieci przedsiębiorstwa rozszerzenie na zarządzanie caģym dostawcą usģug internetowych. "Chmura" to ogólny termin, który oznacza Internet i przetwarzanie w chmurze, i pozwala na umieszczenie większej iloķci materiaģów w chmurze, a mniej na urządzeniach klienckich (np. komputerach PC, serwerach i telefonach). Przezwycięŋa to istniejące bariery, takie jak wzrost pojemnoķci usģug, która zamiast wymagaæ od dostawcy usģug fizycznego rozszerzenia zasobów, moŋe raczej polegaæ na wspólnej wirtualnej rozproszonej puli zasobów sieciowych, przetwarzania i przechowywania. Mapa drogowa badaņ naukowych FIA (Future Internet Assembly - FIA) dla programu "Horyzont 2020" Komisji Europejskiej (H2020) zawieraģa pomysģy i wkģad spoģecznoķci FIA w waŋne tematy badawcze, które powinny zostaæ uwzględnione w programach badawczych H2020. Tematy te są podzielone na trzy gģówne kwestie: interesy gospodarcze i biznesowe; interesy spoģeczne i wyzwania; oraz techniczne zakģócenia i moŋliwoķci. Z perspektywy ekonomicznej i biznesowej, priorytety przyszģych badaņ internetowych w ramach programu H2020 muszą mieæ na celu wpģyw na produkty, usģugi, moŋliwoķci i korzyķci za okoģo 10 lat. Z spoģecznego punktu widzenia musimy wyobraziæ sobie sieæ, która da obywatelom narzędzia biznesowe do kontrolowania swoich danych, wyraŋania swoich praw i wypeģniania swoich zobowiązaņ oraz dziaģania w sposób pewny w cyberprzestrzeni, która jest przeniknięta danymi dotyczącymi wszystkiego i kaŋdego aspektu ŋycia. Jeķli chodzi o aspekty techniczne, jeķli zaģoŋymy, ŋe konwergencja sieci i chmura juŋ się wydarzyģy i patrzymy w przyszģoķæ, będziemy postrzegaæ przyszģy Internet nie jako sieæ, chmurę, pamięæ masową lub urządzenia, ale jako ķrodowisko wykonawcze dla inteligentnych aplikacji, usģug, interakcji, doķwiadczenie i dane. Przyszģa sieæ powinna integrowaæ wiele róŋnych moŋliwoķci poza konwergentnymi sieciami czujników infrastruktury, Internetem, hotspotami, siecią bezprzewodową, siecią rdzeniową - aby zapewniæ znacznie większą pojemnoķæ i zakres potrzebnych usģug. Potrzebujemy nowych interfejsów i trybów interakcji z systemami i urządzeniami sieciowymi, ludžmi i spoģecznoķciami oraz danymi. Będą one stanowiæ odskocznię w kierunku nowych modalnoķci i perspektyw zachęcających do przeģomowych i innowacyjnych rozwiązaņ w celu budowania przyszģego Internetu. Wreszcie, potrzebujemy bezpieczeņstwa Internetu i bezpieczeņstwa jego uŋytkowników online. Rozpatrując wszystkie te obawy ze ķrodowiska badawczego sieci, ewentualne przyszģe programy badawcze zostaģy szeroko omówione w žródģach i. W szczególnoķci:
(i) rozwiązania powinny byæ bardziej ekologiczne dla oszczędnoķci energii; (ii) koncepcja "sieci jako usģugi" wymaga ķciķlejszej wspóģpracy między graczami sieci i usģug; (iii) samoorganizacja i autonomia w zarządzaniu zģoŋonoķcią sieci jest kluczowym wymogiem; (iv) wirtualizacja pozwalająca na sieæ sieci i wspóģdzielenie infrastruktury musi byæ gģęboko zbadana; oraz (v) Mobile Cloud Computing wymaga bardziej kompleksowego podejķcia badawczego. W związku z tym Unia Europejska (UE) zaproponowaģa program partnerstwa publiczno-prywatnego (PPP), którego celem jest dostarczanie rozwiązaņ, architektur, technologii i standardów dla wszechobecnych infrastruktur sieciowych 5G w następnej dekadzie. Oczekuje się, ŋe w 2020 r. przyszģy Internet, tj. Internet 5G, będzie w stanie poģączyæ wszystko wedģug wielu specyficznych wymagaņ aplikacji: ludzi, rzeczy, procesów, centrów obliczeniowych, treķci, wiedzy, informacji i towarów, poģączonych w elastyczny, prawdziwie mobilny i wydajny sposób. W tym ķrodowisku, z niespotykanymi wciąŋ rosnącymi wymaganiami uŋytkowników, wierzymy, ŋe sieæ wymaga skalowalnych, niezawodnych, wydajnych kosztowo i energooszczędnych rozwiązaņ do tworzenia wartoķci dodanych usģug, transportowanych za pomocą zróŋnicowanych gwarancji QoS i szerokiego zakresu opcji QoS Dla klientów. W tym sensie ten rozdziaģ ma na celu przedyskutowanie, jaki moŋe byæ ksztaģt internetowych technologii architektonicznych 5G umoŋliwiających synergiczne podejķcie do SDN, wirtualizacji funkcji sieciowych (NFV), mobilnoķci i zróŋnicowanej kontroli QoS. Ponadto wprowadzamy internetowy protokóģ udostępniania zasobów, który jest w stanie zagwarantowaæ zróŋnicowane QoS przy zwiększonym wykorzystaniu zasobów, bez ponoszenia nadmiernej sygnalizacji lub marnotrawstwa zasobów. Częķæ jest zorganizowana w następujący sposób. Częķæ 2.2 omawia Internet rzeczy i ķwiadomoķæ kontekstową. Sekcja 2.3 zawiera szczegóģowe informacje na temat rekonfiguracji sieci i obsģugi wirtualizacji. W sekcji 2.4 przedstawiamy badania z zakresu zarządzania obsesją oparte na podejķciu ewolucyjnym i czystym podejķciu do Internetu 5G. Sekcja 2.5 omawia obsģugę QoS. Ponadto sekcja 2.6 wprowadza nowy mechanizm kontroli QoS z obsģugą funkcji SDN.
Internet rzeczy i ķwiadomoķæ kontekstowa
Wraz ze wzrostem liczby rozwiązaņ ģączeniowych w porównaniu z wieloma smartfonami, ģączami samochodowymi, czujnikami, urządzeniami domowymi i wieloma innymi rodzajami urządzeņ, liczba podmiotów sieciowych osiąga niespotykany dotąd poziom. Ewolucje internetowe są wymagane nie tylko po to, aby umoŋliwiæ optymalne dziaģanie w tych ķrodowiskach, ale takŋe, aby umoŋliwiæ dalsze rozszerzenie i ulepszenia, biorąc pod uwagę przyszģe przypadki uŋycia, które wykraczają poza adresowanie rozszerzone, takie jak dostarczane przez IPv6. Niezbędne podstawowe funkcje sieciowe, począwszy od zarządzania, toŋsamoķci, bezpieczeņstwa, mobilnoķci i innych, muszą ewoluowaæ w bardziej skalowalny sposób, aby wspieraæ eksplozję urządzeņ, i rzeczywiķcie staæ się Internetem przedmiotów. Podobnym wyzwaniem jest ķwiadomoķæ kontekstowa, która ma na celu wykorzystanie inteligentnych usģug i aplikacji, dąŋąc do wykorzystania wybuchowej iloķci danych kontekstowych opisujących uŋytkowników i ich sytuacje (takie jak lokalizacja, czas itp.) W celu dostosowania ich zachowania (kontekst adaptacja). Oczekuje się, ŋe system internetowy zintegruje funkcje sugerujące uŋytkownikom elementy, które speģniają ich zainteresowania, oraz optymalne preferencje dla konkretnej sytuacji i kontekstu. Technologie te są jednak wciąŋ w powijakach i dalsze badania są uwaŋane za konieczne w wielu dziedzinach, w tym personalizacja, kontrola sieci, wyszukiwanie informacji, eksploracja danych i marketing.
Internet przedmiotów
W ciągu ostatnich kilku lat ewolucja miniaturyzacji elektronicznej umoŋliwiģa poģączenie i integrację moŋliwoķci komunikacyjnych w coraz większej liczbie róŋnych rodzajów urządzeņ, takich jak czujniki. Z kolei dostępnoķæ tych moŋliwoķci ģącznoķci sprzyjaģa ulepszenie istniejących technologii radiowych, a takŋe rozwój nowych technologii. W szczególnoķci uzupeģnienie zestawu skoordynowanych mobilnych sieci bezprzewodowych opartych na makrokomórkach (np. trzeciej generacji - 3G, dģugoterminowej ewolucji - LTE, ogólnoķwiatowej interoperacyjnoķci dla dostępu mikrofalowego - WiMAX) oraz ģącznoķci bezprzewodowej opartej na rywalizacji (np. bezprzewodowa sieæ lokalna - WLAN), widzieliķmy nowe wdroŋenia bezprzewodowe ukierunkowane na Personal Area Networks (PAN), takie jak ZigBee, Instytut Inŋynierów Elektryków i Elektroników - IEEE 802.15.4, DASH7, WirelessHART i Weightless, dodając do powszechnie dostępnych technologii Bluetooth i podczerwieni. Ten wzrost moŋliwoķci komunikacyjnych urządzeņ dodaģ impetu do dobrze zbadanego obszaru bezprzewodowych sieci czujników, zachęcając do ich wdroŋenia w bezprecedensową liczbę nowych przypadków uŋycia, moŋliwoķci biznesowych i wkģadu spoģecznego. Co więcej, rozszerzenie to wykracza poza wyģączne zastosowanie sieci czujników bezprzewodowych w szersze ķrodowisko poģączeņ, obejmujące urządzenia o róŋnym charakterze, od telefonów komórkowych po samochody, sprzęt monitorujący, monitorowanie mediów, automatyzację produkcji, logistykę, wsparcie biznesowe i wiele innych inni. Wraz z heterogenicznym wyzwaniem równoczesnego dotarcia do tych urządzeņ za pomocą róŋnych technologii dostępu, dla róŋnych scenariuszy i przypadków uŋycia, zaczęto opracowywaæ ramy sterowania wspierające te ķrodowiska, wykorzystując koncepcje IP w celu zapewnienia zdalnych procedur osiągalnoķci. W ten sposób narodziģ się Internet przedmiotów. Dostęp do platform urządzeņ zostaģ wzmocniony dzięki dostosowaniom IP, takim jak 6LoWPAN], dzięki czemu zbliŋyģ się on do architektury zorientowanej na usģugi, dodając bogate projektowanie aplikacji i integrację z komunikacją typu maszynowego. Wykorzystując te koncepcje nawet w bardzo prostych urządzeniach elektronicznych, poprzez protokoģy takie jak CoAP z grupy roboczej Constrained RESTful Environments (CoRE) Internetowej Grupy Zadaniowej ds. Inŋynierii Internetowej (IETF), do urządzeņ dodano moŋliwoķci kontrolowania usģug internetowych, co pozwoliģo na prawdziwie zintegrowane i inteligentne wdroŋenia scenariuszy. Koncepcje te byģy aktywnie badane w projektach takich jak SODA (Service Oriented Device and Delivery Architecture), SOCRADES (Service-Oriented Cross-layer infrastructure dla Distributed Smart Embedded Systems, SENSEI (Integracja fizyczna z cyfrowym ķwiatem sieci przyszģoķci) i SmartSantander, które pozwoliģy zmniejszyæ przepaķæ między ķwiatem fizycznym a cyfrowym, i sģuŋyģy do prawdziwej integracji urządzeņ w wielkoskalowe platformy, tworząc Inteligentne Miasto, Inteligentne Rolnictwo i wiele innych scenariuszy, w których informacje uzyskiwane z róŋnych rodzajów czujniki (np. temperatura, wilgotnoķæ, zanieczyszczenie, wideo) zostaģy poģączone z politykami i algorytmami kontrolnymi w celu zautomatyzowania decyzji, które napędzają urządzenia uruchamiające podģączone do platformy (np. zmiana sygnalizacji ķwietlnej w celu zmniejszenia zanieczyszczenia CO2 w zatģoczonych obszarach w Smart Traffic, optymalizacja zuŋycia wody w Scenariusze Smart Utilities, a nawet automatyzacja i automatyczna regulacja c nawadnianie rop w scenariuszach inteligentnego rolnictwa).
W wyniku wystawienia architektur IoT na wiele róŋnych scenariuszy, wpģyw na róŋne obszary badawcze i ich ewolucję, biorąc pod uwagę wyzwania i wymagania ich zastosowania w tych ķrodowiskach. W ten sposób osiągnięto nowe wyniki badaņ w zakresie bezpieczeņstwa, prywatnoķci, efektywnoķci energetycznej i wielu innych obszarów, aby wziąæ udziaģ w ich wkģadzie w tak bogate i róŋnorodne ķrodowiska, jak IoT. Jednak efektem ubocznym jest zwiększone rozmieszczenie platform IoT w róŋnych domenach byģa nieskoordynowana eksplozja przestrzeni rozwiązania. W szczególnoķci róŋne platformy, zģoŋone z róŋnych konfiguracji stosów sieciowych i usģugowych, zostaģy wdroŋone w róŋnych scenariuszach. W ten sposób IoT, zamiast byæ powszechnie stosowanym materiaģem, w rzeczywistoķci generowaģ róŋne pionowe silosy na rozwiązania, w których komponenty naleŋące do kaŋdego innego rozwiązania nie byģy w stanie poģączyæ się lub byæ wymienne, lecz raczej dziaģaģy jako wyodrębnione wyspy. Do tego czynnika przyczyniģy się takie aspekty, jak rozbieŋnoķæ w urządzeniach i interfejsach sieciowych oraz pojemnoķciach urządzeņ, a takŋe róŋne semantyki zaangaŋowanych urządzeņ (np. Czujników i siģowników). W celu uģatwienia przyjęcia i integracji wdroŋeņ IoT w coraz większej przestrzeni aplikacji, dokonano zmiany ksztaģtu paradygmatu, zmieniając pionowe rozwiązania w rozmieszczenie poziome, gdzie róŋne warstwy zapewniają wspóģuŋytkowane podģoŋe, które jest interoperacyjne, wielo-technologiczne, multi-platform i multi-scenario. W ten sposób moŋna wykorzystaæ te same mechanizmy sieciowe, te same platformy poģączeņ urządzeņ i te same warstwy usģug, kontroli i zarządzania w róŋnych scenariuszach. Przyczyniając się do tej zmiany, róŋne projekty przesuwają się ku badaniom nad IoT, takim jak MINDiT, gdzie jeden ogólny interfejs moŋe byæ ponownie wykorzystany do sterowania i uzyskiwania informacji z róŋnych rodzajów urządzeņ w heterogenicznych scenariuszach. Te same koncepcje są równieŋ badane i rozwijane przez nowe generacje projektów badawczych, takich jak IoT-A (Internet Rzeczy - Architektura), i są podstawą dziaģaņ normalizacyjnych, takich jak Maszyna do Maszyny Europejskiego Instytutu Norm Telekomunikacyjnych (ETSI) Standardy maszyn, które stanowią podstawę eksploatacji operatorów telekomunikacyjnych przez platformy dostępu oparte na usģugach. Zamiast osiągaæ ostateczne rozwiązanie lub etap badaņ, Internet przedmiotów wciąŋ ewoluuje. Oprócz ciągģego ujawniania tych koncepcji w nowych scenariuszach, róŋne nowe trendy badawcze wpģywają równieŋ na nowe sposoby myķlenia o IoT, pozwalając na odkrywanie nowych przeģomowych technologii informacyjnych i komunikacyjnych, takich jak Cloud Computing, SDN lub Big Data.
Ķwiadomoķæ kontekstowa
Ķwiadomoķæ kontekstowa zostaģa szeroko zbadana w ramach europejskiego projektu C-CAST, którego gģównym celem jest rozwijanie mobilnej multiemisji multimedialnej w celu wykorzystania coraz większej integracji urządzeņ mobilnych z naszym codziennym ķwiatem fizycznym i ķrodowiskiem. C-CAST zwiększa wykorzystanie ķrodowisk czujników i inteligentnych urządzeņ (a.k.a. smart space), aby umoŋliwiæ nowe wymiary personalizacji globalnego rynku telekomunikacyjnego. Inteligentną przestrzenią w tym względzie moŋe byæ kaŋda dobrze zdefiniowana przestrzeņ zamknięta, taka jak sala konferencyjna lub szkoģa, lub dobrze zaprojektowana otwarta przestrzeņ, taka jak plac miejski lub park narodowy. Zazwyczaj skģada się z wielu heterogenicznych czujników, inteligentnych urządzeņ i kontekstowych zlewów informacji, wraz z serwerami danych z odpowiednimi (lokalnymi publicznymi / ķrodowiskowymi) informacjami, które wspóģdziaģają ze sobą, aby zapewniæ wzbogacone usģugi, a tym samym uģatwiæ pģynne dziaģania uŋytkowników. W literaturze pokrewnej moŋna wskazaæ kilka definicji kontekstu. Kontekst moŋe byæ dowolnym rodzajem informacji, która moŋe byæ wykorzystana do scharakteryzowania sytuacji jednostek (np. osoby, miejsca, obiektu), które są uwaŋane za istotne dla interakcji między uŋytkownikiem a aplikacją, w tym uŋytkownika i samej aplikacji. Przykģady informacji kontekstowych od strony uŋytkownika sieci to lokalizacja geograficzna uŋytkownika, prędkoķæ, kierunek, aktywnoķæ, moc baterii, moŋliwoķci urządzenia, ķrodki transportu, czas bezczynnoķci i tak dalej. Z perspektywy sieci informacje kontekstowe mogą obejmowaæ sytuację przeciąŋenia, wykorzystanie zasobów, nieprzewidywalną zmianę trasy, dostępne punkty dostępu do sieci, statystyki mapowania QoS i róŋne modele QoS. Twierdzi się, ŋe system ķwiadomi kontekstu musi byæ w stanie wyczuæ i zrozumieæ odpowiedzi na pytania generowane z: kto, co, kiedy, gdzie i dlaczego; podczas gdy ķwiadomoķæ kontekstowa jest stanem, w którym urządzenie lub program jest ķwiadomy ķrodowiska i automatycznie wykonuje produktywne funkcje. Oznacza to, ŋe urządzenia i programy zorientowane kontekstowo nie są juŋ pasywnymi istotami czekającymi na instrukcje lub polecenia, a zamiast tego są ŋywe i zdolne do inteligentnych zachowaņ. Sieci i usģugi wykorzystywaģyby odpowiednie informacje kontekstowe, aby dostosowaæ swoje zachowanie do zmieniających się warunków w bardzo dynamiczny sposób. Szybko rozwija się takŋe wszechobecna technologia komputerowa, a takŋe kilka propozycji wykorzystujących ķrodowiska bogate w czujniki i urządzenia do spersonalizowanego i wszechobecnego przetwarzania zorientowanego na czģowieka, jak widaæ w projektach Aura, Oxygen, BlueSpace i Cooltown. W ten sam sposób w spoģecznoķci pojawiģo się wiele propozycji oprogramowania warstwy poķredniej zorientowanego na usģugi, takich jak Gaia Project, SOCAM, Context Toolkit, CoBrA i CMF. Więcej przykģadów aplikacji kontekstowych moŋna równieŋ znaležæ w odnoķnikach. Ķwiadomoķæ kontekstu sieciowego to zdolnoķæ systemu do wykorzystywania informacji o kontekķcie sieciowym do samodzielnej adaptacji lub do ķwiadczenia usģug. Lee i in. uŋyj serwera kontekstowego i serwera komunikatów Context-Aware i zaproponuj usģugę przesyģania wiadomoķci opartą na kontekķcie "Doģącz wiadomoķæ" z drzewami multiemisji zbudowanymi odgórnie, podczas gdy oczekują, ŋe format pakietu będzie bardziej elastyczny w przyszģej sieci. Ocampo i in. wykazaæ klasyfikację przepģywu opartą na kontekķcie i stwierdziæ, ŋe obecnie nie jest moŋliwe wszechstronne uwzględnienie i zaklasyfikowanie przepģywów usģug pod względem ich szerszego kontekstu, przy jednoczesnym uwzględnieniu parametrów wewnętrznych i zewnętrznych względem samego przepģywu (takich jak rodzaj aplikacji, która go wygenerowaģa) , cechy urządzenia, które będzie go uŋywaæ, oraz dziaģania uŋytkownika, który go wygenerowaģ).
Obsģuga rekonfiguracji sieci i wirtualizacji
Wzrost liczby poģączeņ sieciowych, poczynając od mobilnych smartfonów, a koņcząc na ķwiatģowodowych dekoderach w domu, a takŋe ciągģym zwiększaniu liczby usģug online, obecnie umniejsza starsze technologie wdraŋania i strategie operatorów. Chociaŋ silna baza klientów jest celem biznesowym dla operatorów i dostawców usģug, są one kosztowne, tworząc skomplikowane scenariusze jakoķci usģug i zwiększając wydatki kapitaģowe (wydatki kapitaģowe) i wydatki operacyjne (Opex) na wsparcie nowych partii klientów. Obecnie, aby wspieraæ tę rosnącą bazę klientów i rozszerzyæ ģącznoķæ online na nowe obszary, naleŋy wdroŋyæ nowe ģącza i zwiększyæ przepustowoķæ, a takŋe więcej infrastruktury usģugowej i centrów danych, co znacznie zwiększa koszty związane z tymi rozszerzeniami. Nowe technologie wspomagające zostaģy zbadane i zastosowane do nowych strategii dynamicznego dostosowywania sieci i usģug zgodnie z zapotrzebowaniem. W poniŋszych podrozdziaģach skupiamy się na dwóch najbardziej wpģywowych mechanizmach dla nadchodzącego 5G, mianowicie na programowaniu sieciowym i wirtualizacji funkcji sieciowych. Pierwszy umoŋliwia dynamiczną rekonfigurację oprogramowania i aspekty przekazywania sieci poprzez logiczne oddzielenie ķcieŋek sterowania i danych. W tym drugim przypadku operatorzy sieci i usģug korzystają z istniejącej puli zasobów sieciowych i przetwarzających, aby wygenerowaæ niezbędną infrastrukturę bazową w wirtualny sposób, zamiast fizycznie wdraŋaæ nową infrastrukturę sieciową i serwerową.
Sieci zdefiniowane programowo
Ciągģa ewolucja technologii sieciowych motywuje pojawianie się nowych mechanizmów kontroli i strategii, z zamiarem nie tylko testowania nowych procedur sieciowych, ale w rzeczywistoķci ich obsģugi, takich jak SDN. Podejķcie SDN obejmuje logicznie scentralizowaną jednostkę, nazywaną kontrolerem, która zarządza podstawową pģaszczyzną danych sieciowych za pomocą zorientowanego na usģugi interfejsu API, który pozwala mu skonfigurowaæ tabele przesyģania sprzętu sieciowego (np. Przeģączniki) na temat reakcji na przychodzące pakiety i przepģywy . Strategia ta zapewnia oddzielenie pģaszczyzn danych i sterowania i jest realizowana za pomocą procedur oprogramowania. Rysunek przedstawia przykģad dziaģania SDN. W tym scenariuszu kontroler SDN (SDNC) odpowiada za obsģugę trzech róŋnych przeģączników OpenFlow.
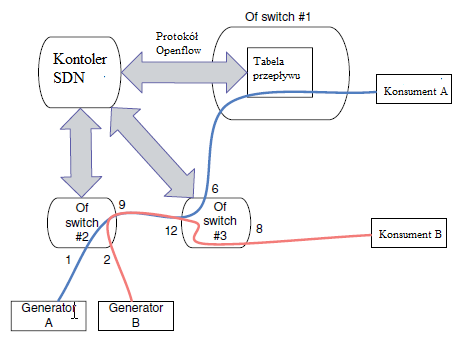
Podģączony do OpenFlow Switch nr. 1 to dwa generatory informacji. Generator A generuje informacje o "stopniu produkcji" (tj. regularny ruch), którego celem jest konsument A, podczas gdy generator B jest uŋywany do testowania nowego protokoģu. W tej koncepcji twórcy tego protokoģu chcieli oceniæ jego wydajnoķæ w sieci produkcyjnej. W ten sposób kontroler zostaģ skonfigurowany w taki sposób, ŋe po wykryciu protokoģu ruchu generowanego przez Generator B, związane z nim informacje powinny byæ przekazywane do Konsumenta B. Liczby na rysunku wskazują numery portów przeģączników. W tym przykģadzie, gdy ruch z Generatora B osiągnie wartoķæ Switch no. 1, kontroler kontaktuje się za pomocą protokoģu OpenFlow. Kontroler, dzięki wstępnie skonfigurowanej wiedzy o topologii sieci, jest w stanie okreķliæ, ŋe ostatecznym miejscem docelowym dla tego rodzaju ruchu powinien byæ Konsument B, a nie Konsument A. W ten sposób generuje zestaw poleceņ OpenFlow, w kierunku zarówno Przeģącznika 1, jak i Przeģącznik 2. W pierwszym przypadku sterownik konfiguruje przeģącznik za pomocą oprogramowania, aby dodaæ wirtualny znacznik do wszystkich pakietów o pochodzeniu w Generatorze B. W tym drugim sterownik konfiguruje Przeģącznik 2, instruując, ŋe wszystkie pakiety z takim znacznikiem osiągną numer portu 12 naleŋy przekazaæ do portu numer 8 (zamiast domyķlnej zasady wysyģania caģego ruchu do portu nr 6). W ten sposób róŋne mechanizmy sieciowe (tj. Routing, przekazywanie, kontrola dostępu) są konfigurowalne przez kontroler w sieci, obsģugując dynamiczne korekty topologii sieci i rekonfigurację. Ponadto ewolucja infrastruktury staje się procesem uproszczonym, poniewaŋ ręczna rekonfiguracja sieci nie jest juŋ wymagana, jak równieŋ ģagodzi integrację zģoŋonych procedur obsģugi sprzętu. W związku z tym infrastruktura moŋe ewoluowaæ ģatwiej przy uŋyciu ujednoliconej abstrakcji, a takŋe przystosowaæ się do nowych ķrodowisk sieciowych, dzięki powstaniu nowych mechanizmów sieciowych, takich jak Cloud Computing, Internet rzeczy i inne. Ze względu na swój charakter oprogramowania pojawiģy się obawy i wątpliwoķci dotyczące aspektów takich jak skalowalnoķæ. Niemniej jednak oceny wykazaģy, ŋe problemy ze skalowalnoķcią nie są wynikiem samej architektury SDN, co pozwala na rozwiązanie problemów przy jednoczesnym zachowaniu zalet architektury SDN. Dodatkowa elastycznoķæ zapewniona przez jego projekt, jego gģówny kluczowy atrybut, pozwala sieciom na utrzymanie wydajnoķci przesyģania i wysokiej dynamiki dzięki konfiguracji w locie i wysokiej wydajnoķci dzięki zoptymalizowanemu routingowi i redukcji kosztów. Aspekty te przyciągnęģy uwagę nie tylko producentów, ale takŋe operatorów, a nawet centrów danych (np. Google). Niemniej jednak gģównym zastosowaniem w ostatnich latach byģ mechanizm wspierający wielkoskalowe federacyjne urządzenia testowe do badaņ, wzmacnianie wysiģków, takich jak projekt badawczy OFELIA, GENI (globalne ķrodowisko dla innowacji sieciowych) i sieæ testowa nowej generacji JGN- X w Japonii. Wdroŋenie ķrodowisk opartych na SDN zostaģo ponownie wdroŋone w postaci implementacji OpenFlow OpenFlow. Pierwotnie zaprojektowany do celów badawczych, pozwalający na testowanie nowych protokoģów w rzeczywistych sieciach produkcyjnych, obecnie OpenFlow moŋna znaležæ w wielu produktach komercyjnych. Sieci wyposaŋone w to oprogramowanie skģadają się z przeģączników OpenFlow i kontrolerów OpenFlow. Ten pierwszy integruje moŋliwoķci SDN z przeģącznikami, sterowanymi przez API OpenFlow. Ten ostatni uŋywa tego samego API do sterowania przeģącznikami OpenFlow pod względem tworzenia i utrzymywania przepģywów. Konkretny przykģad zastosowania przedstawiono na rysunku,
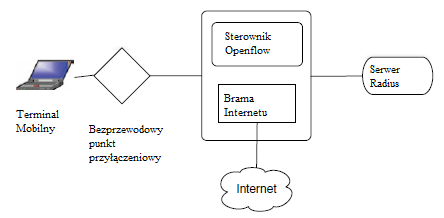
gdzie OpenFlow jest uŋywany do przechwytywania lub wstrzykiwania wiadomoķci uwierzytelniających 802.1X, pozwalając kontrolerowi (przy pomocy okreķlonej logiki aplikacji) dziaģaæ jako 802.1X Authenticator i Radius Client, w sposób specyficzny dla uŋytkownika. Koncepcje SDN napędzają jednoczeķnie róŋne obszary sieciowe i biznesowe, umoŋliwiając im niezbędną elastycznoķæ w zakresie konfiguracji i kontroli, zapewniając jednoczeķnie inspirację dla nowych scenariuszy. Na przykģad aspekty SDN zaczęģy ksztaģtowaæ operacyjny rdzeņ aspektów Cloud Computing poprzez integrację protokoģu OpenFlow z oprogramowaniem Cloud Computing, takim jak OpenStack. W tym przypadku dynamiczne moŋliwoķci oferowane przez OpenFlow API są wykorzystywane do obsģugi aspektów sieci wirtualizacji, abstrahowania aplikacji specyficznych dla sieci i obniŋenia kosztów operacyjnych przeģączania sieci. Inne kierunki badaņ to takŋe wykorzystanie mechanizmów SDN, które tradycyjnie są stosowane w sieciach z rdzeniem staģym, w sieciach bezprzewodowych, zarówno w sieciach operatorów komórkowych, jak i sieciach WLAN i Mesh. Wreszcie trwają prace, w których SDN jest podstawą nowatorskich przeksztaģceņ warstwy sieciowej. Jednak scentralizowany charakter mechanizmów kontrolnych, jak równieŋ trudna trakcja przy wdraŋaniu SDN w przeģączaniu producentów, w poģączeniu z istnieniem róŋnych wersji protokoģu OpenFlow obsģugiwanych na róŋnych urządzeniach, utrudniają wysiģki wdroŋeniowe i wymagają bardziej pģynnej integracji awanse.
Wirtualizacja funkcji sieciowych
W NFV ķwiadczenie usģug przechowywania, przetwarzania i obsģugi przez sieæ wykracza poza to, co jest zwykle oferowane w Cloud Computing, i faktycznie pozwala na dostarczanie wirtualnych funkcji sieciowych w krawędzi sieci, dzieląc aspekty Network-as-a-a-Service ( NaaS). W związku z tym techniki wirtualizacji umoŋliwiają wdroŋenie funkcji sieciowych w oprogramowaniu, które moŋe dziaģaæ niezaleŋnie od podstawowego sprzętu serwerowego, jak opisano na rysunku
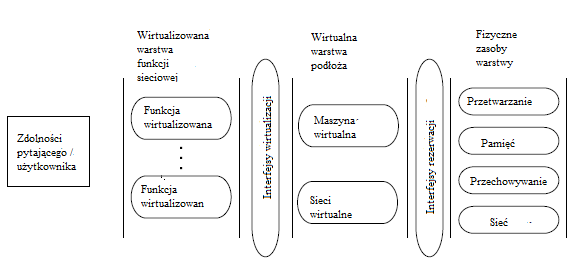
W tym przykģadzie operator sieci zapewnia funkcję zwirtualizowaną (np. Serwer aplikacji) klientowi (np. Dostawcy usģug). Aby operowaæ takim scenariuszem w podejķciu NFV, operator wykorzystuje swoje podstawowe zasoby sieci, przetwarzania i pamięci w tak zwanej warstwie zasobów fizycznych. Ta warstwa stanowi bardziej związane ze sprzętem aspekty udostępniania funkcji przez operatora. Jednak w tej warstwie zasoby te pojawiają się jako surowe agregaty elementów obliczeniowych i sieciowych. Korzystając z interfejsów rezerwacji, moŋna zaŋądaæ tych zasobów za poķrednictwem ķrodowiska wykonawczego wirtualizacji i zarezerwowaæ na sprzęcie. Ta warstwa, nazwana Warstwą Wirtualnego Substratu, jest w stanie zastosowaæ kolejnoķæ logiczną dla róŋnych zasobów sprzętowych, udostępnioną przez Warstwę Zasobów Fizycznych. W ten sposób takie zasoby moŋna logicznie agregowaæ w jedną lub kilka maszyn wirtualnych (tj. Komponując wirtualny typ elementu obliczeniowego, w którym funkcje mogą byæ przechowywane i obsģugiwane), a takŋe sieci wirtualne (tj. Zapewniając niezbędną strukturalną ģącznoķæ dla maszyn wirtualnych, biorąc pod uwagę róŋne polityki routingu i biznesowe). Ten poziom zwirtualizowanych zasobów zapewnia ponadto interfejs wirtualizacji, umoŋliwiający wdraŋanie róŋnych wirtualizowanych funkcji w tzw. Sieciowej funkcji wirtualizacji. W związku z tym podstawowy sprzęt dostarczany przez operatora moŋe zostaæ zwirtualizowany w logiczną strukturę, zarówno pod względem sieci, jak i przetwarzania, w której moŋna wirtualizowaæ róŋne usģugi i funkcje. W ten sposób rzeczywiste podmioty dziaģające w sieci mogą byæ wirtualizowane w wielu wersjach i na wiele sposobów, umoŋliwiając szybkie skalowanie usģug i funkcji zgodnie z wymaganiami, przy jednoczesnym zmniejszeniu dojrzewania i czasu do wprowadzenia na rynek dzięki obniŋkom Capex. W rezultacie pokonywane są bariery związane z zastrzeŋonym sprzętem, co znacznie upraszcza wdraŋanie nowych usģug sieciowych. Aby jeszcze bardziej pomóc w konsolidacji tego poglądu, ETSI stworzyģo NFV Industry Specification Group, co zaowocowaģo stworzeniem pięciu specyfikacji (tj. Przypadków uŋycia, ram architektonicznych, terminologii, wymagaņ wirtualizacji i dowodów koncepcji), a takŋe wczeķniejszej biaģej księgi identyfikującej gģówne korzyķci i punkty odniesienia [ W tym kontekķcie wspierająca rola mechanizmów SDN we wdroŋeniach NFV jest wyražnie okreķlona jako wsparcie dla usprawnienia integracji róŋnych rodzajów sieci przeģączających i kontrolowania ich zachowaņ związanych z przekazywaniem poprzez wykorzystanie specyfikacji abstrakcji zdefiniowanych przez oprogramowanie. W ten sposób, jak pokazano na rysunku
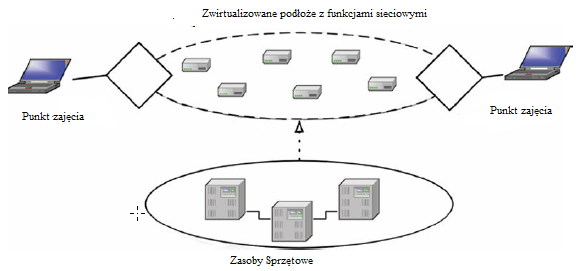
Zasoby sieciowe są budowane jako reprezentacje dziaģające na warstwie zwirtualizowanej zapewniane przez zasoby sprzętowe w fizycznych lokalizacjach. Pozwala to na większą elastycznoķæ wdraŋania i dziaģania sieci, umoŋliwiając dodawanie lub usuwanie usģug (które równieŋ mogą byæ same w sobie infrastrukturą i mechanizmami sieciowymi) na ŋądanie.
Ten wstępny etap specyfikacji, oparty na zainteresowaniu wielu stron, motywuje do opracowania genialnych nowatorskich wyników badaņ, takich jak przyjęcie mechanizmów NFV w architekturach operatorów mobilnych. Jednak prawdziwa siģa tej inicjatywy polega na przeģomowych moŋliwoķciach, co przekģada się na nowe moŋliwoķci wspóģpracy biznesowej i wspóģpracy z przewožnikami, a takŋe na zwiększenie moŋliwoķci wspóģpracy między sektorami IT i telekomunikacyjnym. Na przykģad interakcja (zarówno w zakresie federacji, jak i polityk między domenami) między róŋnymi dostawcami NFV będzie musiaģa dodaæ dodatkową warstwę zģoŋonoķci w stosunku do ogólnego projektu NFV, który moŋe nie byæ ģatwy do wdroŋenia w istniejących modelach biznesowych.
Mobilnoķæ
Obecny Internet jest ograniczony pod względem mobilnoķci usģug, poniewaŋ architektura internetowa nie uwzględniģa skutecznie dostępu mobilnego. Jednak znaczenie mobilnoķci staje się coraz bardziej wyražne, poniewaŋ inteligentne urządzenia są wypeģniane zaawansowanymi funkcjami przetwarzania procesorów mobilnych i funkcjami wielomodowymi, aby wspieraæ interoperacyjnoķæ w szerokim zakresie technologii heterogenicznego dostępu, takich jak 3G / LTE i WiMAX, a takŋe WiFi. Wyzwaniem dla wsparcia mobilnoķci w obecnym projekcie internetowym jest sposób obsģugi adresowania IP, a wiele wysiģków badawczych zmierzających do rozwiązania tego dylematu opieraģo się gģównie na dwóch podejķciach: z jednej strony, aby rozszerzyæ architekturę Internetu poprzez wprowadzenie nowych jednostek wsparcia mobilnoķci i protokoģy graniczące bardziej z podejķciem ewolucyjnym; z drugiej strony, aby przebudowaæ paradygmat sieciowy, przyjmując podejķcie czysto-ģupkowe. Pierwszy z nich koncentruje się na zapewnieniu realistycznych i odpowiednich rozwiązaņ w zakresie mobilnoķci w obecnej architekturze Internetu, tak aby zbliŋyæ się do wykorzystania na rynku, podczas gdy ten drugi stara się skupiæ na rozwiązaniu fundamentalnego problemu wynikającego z obecnej architektury internetowej, z nowym paradygmatem. Jednak oba podejķcia projektowe zmierzają w kierunku Internetu 5G, ale grają na róŋnych poziomach.
Podejķcie ewolucyjne z bieŋącego Internetu
W tym podejķciu dobrze znanym rozwiązaniem jest Mobile IPv6 (MIPv6), który wprowadza agenta macierzystego (HA) do zarządzania informacjami o powiązaniach między węzģem mobilnym (MN) a adresem macierzystym (HoA) i opieką nad adresami ( CoA). MIPv6 przedstawiģ przeģomowy sposób rozszerzenia architektury Internetu na wsparcie mobilnoķci. Aby wyeliminowaæ zaangaŋowanie gospodarza w aktualizację mobilnoķci, Proxy Mobile IPv6 (PMIPv6) pojawiģ się z koncepcją zarządzania mobilnoķcią opartą na sieci, wykazując doskonaģą wydajnoķæ mobilnoķci i przyjęty w kilku organach normalizacyjnych. Badania nad rozszerzeniem oparte na PMIPv6 są obecnie kontynuowane w celu zwiększenia jakoķci usģug uŋytkownika podczas mobilnego. Obecnie tendencja badawcza w zakresie mobilnoķci IP zmienia się w kierunku projektowania mobilnoķci opartej na pģaskiej zasadzie, zwracając uwagę na problemy wprowadzone przez podejķcie do zarządzania mobilnoķcią scentralizowaną (CMM), na którym zbudowano MIP i PMIPv6. CMM definiuje się tak, aby korzystaģa z centralnie rozmieszczonych kotwic mobilnoķci, gdzie ogromny ruch MN w sieci operatora jest zarządzany przez tę samą kotwicę. Powoduje to powaŋne problemy z wydajnoķcią, takie jak pojedynczy punkt awarii spowodowany nadmiernym obciąŋeniem przetwarzania, nieoptymalny routing przez zawsze podróŋowanie przez punkt kontrolny i niepotrzebne rezerwowanie zasobów w celu ustanowienia i utrzymania tuneli IP dla MN, nawet nie mobilne. Pomysģ dotyczący wyŋej wymienionych problemów logicznie czyni obecną architekturę komórki "bardziej pģaską", zasadniczo zmniejszająca obciąŋenie ruchem i umoŋliwiająca niezawodne dziaģanie sieci, a takŋe poprawiająca wraŋenia uŋytkownika podczas przemieszczania się. Pomysģ ten podzielony jest na dwa kierunki technologiczne: pierwszym podejķciem jest wykorzystanie wewnętrznego protokoģu routingu IP, na przykģad Border Gateway Protocol (BGP), który aktualizuje ķcieŋkę routingu poprzez reklamowanie nowo przypisanego adresu IP doģączonego MN; drugie podejķcie polega na rozģoŋeniu funkcji kotwiczenia mobilnoķci na krawędzie. W pierwszym przypadku osiągalnoķæ MN jest zapewniona podczas przebywania w domenie bez uŋycia zakotwiczenia mobilnoķci. Jednak wydajnoķæ przeģączania zaleŋy od operacji routingu, więc na opóžnienie przeģączania ma wpģyw czas konwergencji routingu wewnątrz domeny, a częste aktualizacje routingu wprowadzają burzę rozgģoszeniową w domenie, jak wskazano w odnoķniku. Jeķli chodzi o to drugie podejķcie, przedstawiono wiele propozycji i ponownie moŋna sklasyfikowaæ rozwiązania za pomocą częķciowo rozproszonych i w peģni rozproszonych modeli, jak pokazano na rysunku, w zaleŋnoķci od tego, czy pģaszczyzna sterowania jest dystrybuowana w celu uzyskania profilu mobilnoķci MN, czy nie
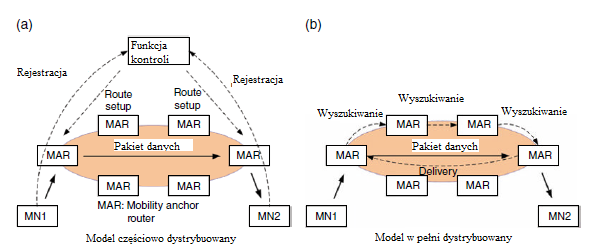
Zbadano rozproszoną architekturę mobilną i metody aplikacji oparte na rozproszonym zarządzaniu mobilnoķcią (DMM) - zaproponowane przez IETF DMM WG (grupa robocza ds. Rozproszonego zarządzania mobilnoķcią w Internet Engineering Task Force) - koncepcja byģa gģównie analizowana w projektach finansowanych przez UE 7PR, takich jak MEDIEVAL (Transport multimedialny dla mobilnych aplikacji wideo) i MEVICO (Ewolucja sieci mobilnych dla doķwiadczenia w komunikacji indywidualnej). W MEDIEVAL, rozproszona architektura mobilna zostaģa zaprojektowana przy wsparciu między warstwami, szczególnie skupiając się na skutecznym dostarczaniu wideo z interaktywnymi transmisjami wideo i osobistymi, itd. W MEVICO, rozproszona architektura mobilnoķci dostosowana do Projektu Partnerskiego 3rd Generation (3GPP) Evolved Packet System (EPS) zostaģ omówiony i zaprezentowany w synergii z inteligentnym sterowaniem ruchem, z uwzględnieniem przeniesienia PDN GW (Packet Data Network Gateway) lub P-GW, jako opcja osiągnięcia optymalnego routingu w prezentowanej architekturze. Dla znormalizowanej architektury IETF DMM WG zakoņczyģ definiowanie wymagaņ dla DMM i badanie analizy luk w istniejących protokoģach mobilnoķci IP z wymienionymi wymaganiami. Wszelkie dalsze rozwiązania będą oparte na wynikach analizy luk. Aby pokazaæ dowód koncepcji wpģywu ruchu rozproszonego na sieci DMM, przeprowadziliķmy symulację danej topologii sieci przy uŋyciu Matlab. Proxy Mobile IPv6 (PMIPv6) jest porównywany jako docelowy protokóģ mobilnoķci IP zgodnie z podejķciem CMM. Rysunek pokazuje topologię sieci zastosowana w naszej symulacji.
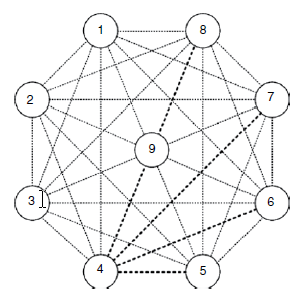
Pokazane węzģy reprezentują routery wykonujące zarządzanie mobilnoķcią zdefiniowane odpowiednio przez DMM i PMIPv6. Nazywamy routerami węzģów rozróŋnienie od węzģów mobilnych lub węzģów korespondencyjnych. Bardzo waŋne jest, aby mieæ topologię do badania obciąŋenia sieci naģoŋonego na mobilne sieci szkieletowe. Dana topologia dobrze radzi sobie z bardzo gęstym ķrodowiskiem mobilnym, w którym uŋytkownicy są bardzo zatģoczeni przez stan mobilny i są otoczone przez wiele budynków skģadających się z duŋej liczby mikrokomórek. Dla PMIPv6, MAG (mobilne bramy dostępu) są umieszczone na krawędziach (od 1 do 8), a LMA (lokalna kotwica mobilnoķci) (węzeģ 9) jest umieszczony w centrum topologii, podczas gdy DMM zabiera wszystkie routery brzegowe jako mobilnoķæ kotwice, które są nazywane Rozproszonym Ruterem Mobilnoķci (DMR) z węzģa 1 do węzģa 9. W celu uczciwego porównania pod względem wpģywu routingu mobilnoķci, węzeģ 9 jest uŋywany do zwykģego celu routingu pakietów IP. CN znajdują się na dowolnych routerach krawędziowych. Linie przerywane pokazują wszystkie dostępne ķcieŋki routingu do wysyģania pakietów między routerami. Jednak pakiety są przesyģane z najkrótszą ķcieŋką routingu między routerami brzegowymi MN i CN. Przykģady dostarczania pakietów dla PMIPv6 i DMM są następujące. CN i MN są doģączone odpowiednio do routerów 1 i 4, a MN przechodzi do routerów 5, a następnie 6. W PMIPv6 pakiet wysģany przez CN przechodzi przez routery 1 → 9 → 4, więc gdy MN porusza się do routera 5, ķcieŋka routingu zostanie zmieniona w ten sposób, 1 → 9 → 5. W DMM pakiet wysģany przez CN jest kierowany bezpoķrednio z routerów 1 do 4 (1 → 4) przez regularny routing IP. Gdy MN przejdzie do routera 5, pakiet przejdzie przez routery 1 → 4 → 5. Z symulowanej operacji routingu w topologii zmierzyliķmy liczby zakotwiczonych pakietów i niepotwierdzonych pakietów, w których nie zakotwiczone pakiety są zdefiniowane jako pakiety dostarczane przez regularny routing IP, nie opierając się na punkcie kontrolnym mobilnoķci. W naszej symulacji modelowanie matematyczne jest częķciowo wykorzystywane do modelowania efektu dģuŋszego routingu, poniewaŋ węzeģ MN oddala się bardziej od swojej kotwicy, co powinno zostaæ uwzględnione w rozwiązaniu zarządzania mobilnoķcią opartym na kotwicy poprzez umieszczenie innego wspóģczynnika wagi na ķcieŋkach routingu . Więcej szczegóģów dotyczących ustawieņ symulacji i modelu kosztów zdefiniowanych moŋna znaležæ w. Następujące wartoķci parametrów z literatury są uŋywane domyķlnie w symulacji; rozmiar pakietu wynosi 1500 bajtów, caģkowita liczba CN wynosi 10, a szybkoķæ odbioru pakietu w sesji jest ustawiona na 200 (pkt / s). Koszt dostarczenia pakietu jest wyraŋony jako iloczyn dģugoķci wiadomoķci i odlegģoķci przeskoku routingu, a następnie jednostka wynosi KB Ũ chmiel. Ķredni czas przebywania MN wynosi 600 sekund, a ķredni czas trwania sesji MN to 360 sekund. Wyniki uzyskuje się ķrednio z 10 000 przebiegów symulacji. Stosunek zakotwiczonych pakietów jest uzyskiwany jako liczba zakotwiczonych pakietów w stosunku do caģkowitej liczby pakietów kierowanych lub przetwarzanych w węžle. PMIPv6 umoŋliwia lokalne trasowanie MAG dla koņcowych terminali mobilnych, gdzie są one poģączone z tym samym MAG. Gdy dwa terminale mobilne są pod tym samym MAG pod lokalnym routingiem MAG wģączonym przez sieæ PMIPv6, pakiet wysģany przez MN nie przechodzi przez LMA, ale jest przesyģany lokalnie. Tak więc wszystkie niepotwierdzone pakiety uzyskane w PMIPv6 są zliczane przez lokalny routing MAG PMIPv6. Liczba niepotwierdzonych pakietów (wynikających z lokalnego routingu MAG w PMIPv6) jest agregowana i wyķwietlana na pozycji routera 9, aby zapewniæ lepsze porównanie wizualne w wyraŋaniu stosunku pakietów niepotwierdzonych przez badanie wszystkich routerów z perspektywy kotwicy. W DMM nie zakotwiczone pakiety są zliczane, gdy MN pozostaje na routerze kotwiczącym kaŋdej sesji, z którą związany jest MN. Stosunek pakietów zakotwiczonych waha się od 0,035 do 0,066 we wszystkich DMR, podczas gdy stosunek wynosi 0,8768 na pojedynczej LMA w PMIPv6. Biorąc pod uwagę, ŋe liczba routerów zakotwiczonych w DMM wynosi 8, moŋemy po prostu wyobraziæ sobie, ŋe stosunek kosztu zakotwiczonego pakietu na pojedynczym DMR byģby 0,1096 ķrednio (po prostu dzieląc 0,8768 przez 8). Jednak stosunek pakietów zakotwiczonych w kaŋdym DMR w DMM jest 13 do 25 razy niŋszy niŋ stosunek na LMA w PMIPv6. Ta poprawa w zmniejszaniu liczby zakotwiczeņ pakietów jest wynikiem większej liczby niepotwierdzonych pakietów w porównaniu z zakotwiczonymi pakietami w DMR. To pokazuje, ŋe DMM ma duŋy wpģyw na zmniejszenie zakotwiczenia pakietu dzięki dynamicznemu kotwiczeniu mobilnoķci. Ponadto pokazuje, ŋe stosunek pakietów zakotwiczonych jest siedmiokrotnie większy niŋ wspóģczynnik niezakotwiczonego kosztu pakietu w PMIPv6, mimo ŋe routing lokalny MAG jest wģączony. Poķrednio pokazuje, ŋe lokalny routing MAG PMIPv6 na scentralizowanym podejķciu do mobilnoķci nie jest tak skalowalny w redukcji kosztów kotwiczenia jak DMM. Zwiększenie czasu przebywania oznacza, ŋe MN porusza się z niŋszym wskažnikiem mobilnoķci. W PMIPv6 liczba zakotwiczonych pakietów i niepotwierdzonych pakietów nie zmienia się znacząco w podanym zakresie ķredniego czasu pobytu, podczas gdy w DMM liczba zakotwiczonych pakietów stopniowo maleje, a liczba niezakotwiczonych pakietów wzrasta. Dzieje się tak, poniewaŋ MN spędzaģ więcej czasu na routerach, gdzie odlegģoķci trasowania są stosunkowo krótsze od kotwic, co prowadzi do wyŋszego ķredniego czasu przebywania i zmniejszonej liczby przekazaņ.
Podejķcie "czysto-ģupkowe"
Ewolucyjne podejķcie z obecnego Internetu opiera się na stylu "ģatania", co powoduje rozszerzenie funkcjonalne na ŋądanie o nowe usģugi lub technologie dostępu. To dodaje potknięcia blokujące obecną architekturę Internetu, co utrudnia innowacje i zrównowaŋony rozwój usģug internetowych. Z tego powodu podejķcie "czystego ģupu" jest znacznie uwzględniane i przyjmowane w róŋnych przyszģych internetowych projektach badawczych. Future Internet (FI) ogólnie uwaŋa, ŋe kwestie mobilnoķci oraz ogólne wyzwania związane z Internetem są rozwiązywane. Istnieje wiele projektów FI opartych na podejķciu "czystego ģupu", ale skupiamy się na projektach ukierunkowanych na mobilnoķæ, krótko wprowadzając gģówne zasady projektów w zakresie wsparcia mobilnoķci. MobilityFirst zostaģ przeprowadzony w Stanach Zjednoczonych w ramach przyszģych badaņ nad architekturą internetową, szczególnie ze względu na fakt, ŋe obecny Internet jest przeznaczony do ģączenia staģych punktów koņcowych. MobilityFirst rozwaŋa mobilnoķæ urządzeņ, treķci i sieci. MobilityFirst integruje domeny sieci heterogenicznej, takie jak sieæ Ad-hoc i sieæ opóžniająca opóžnienia (DTN), które mogą byæ równieŋ zapewnione dla pģynnej mobilnoķci. Zgodnie z podstawowymi zasadami MobilityFirst proponuje podejķcie routingu hybrydowego ID-LOC, które jest stosowane adaptacyjnie, w zaleŋnoķci od dynamiki sieci. Podejķcie to ma zasadniczo charakter LOC, aczkolwiek istnieje nieodģączna moŋliwoķæ wykonywania routingu opartego na ID, równieŋ z powodu pewnej zmiany topologii sieci. MobilityFirst dodaje moŋliwoķci przechowywania do routerów. Za pomocą funkcji routera proponowany jest protokóģ routingu z pamięcią masową (STAR) i segmentowy transport hop-by-hop, który rozwiązuje problemy z dostarczaniem danych z podejķcia opartego na hostingu zorientowanego na koņcowy model komunikacji i ostatecznie zapewnia lepszą QoE uŋytkownika. 4WARD - europejski projekt badawczy 7PR - przedstawiģ nowy paradygmat o nazwie "Sieæ informacji", w którym obiekty informacyjne nie są związane z komunikacją opartą na hostach. Częķci badawcze skģadają się z wirtualizacji sieci (VNet), zarządzania siecią (INM), sieci informacji (NetInf) oraz przekazywania i multipleksowania dla ķcieŋki ogólnej (ForMux). W szczególnoķci, w odniesieniu do wsparcia mobilnoķci, ForMux zaproponowaģ zakotwiczenie dynamicznej mobilnoķci (DMA), mobilnoķæ bez zakotwiczenia (AM) i wielopoziomowe End-to?End Mobility (MEEM), które są projektowane indywidualnie dla sesji krótkotrwaģych, ruchu multiemisji i ruchu "koniec do koņca" w czasie rzeczywistym za poķrednictwem heterogenicznych technologii. DMA opiera się na peģnej dystrybucji funkcji wspierających mobilnoķæ między węzģami dostępowymi (AN) i terminalami, co moŋe byæ podobne do koncepcji zarządzania rozproszoną mobilnoķcią, o której mowa w sekcji 2.5.1. Gdy terminal z wieloma interfejsami porusza się w sieci heterogenicznej, jego przepģywy ruchu są zakotwiczone na początkowej obsģugującej sieci AN, która następnie zapewnia niezbędne poķrednie poģączenia z AN, do których terminal jest obecnie podģączony. AM uŋywa róŋnych adresów dla lokalizacji i identyfikatorów hostów w sieci oraz wģaķciwego schematu adresowania i nazewnictwa, który implementuje podziaģ lokalizatora / identyfikatora przez uŋycie róŋnych punktów koņcowych (EP). Gģówną zasadą jest komunikowanie się między EP wzajemnie poprzez zdefiniowaną funkcję bindowania. Gdy pojawia się ruchliwoķæ, ustanawiane jest nowe wiązanie, czyli wiązanie między EP2 i EP5 . W porównaniu z metodami tunelowania dostarczanymi przez róŋne protokoģy mobilnoķci, takie jak MIP i PMIPv6, koncepcja AM umoŋliwia lokalny routing, a tym samym prowadzi do zmniejszenia opóžnienia transmisji i mniejszego wykorzystania przepustowoķci. MEEM to mechanizm zarządzania mobilnoķcią zdefiniowany w architekturze Generic Path (GP), w której mobilnoķæ jest obsģugiwana przez terminale wielopunktowe. Terminale mobilne wyposaŋone w multi-interfejs mogą jednoczeķnie ģączyæ się z róŋnymi sieciami za pomocą kilku interfejsów. Dlatego teŋ koņcowy GP skģada się z kilku sub-GP-GP. Mobilnoķæ związana z tymi interfejsami jest obsģugiwana w sposób kompleksowy, wykorzystując multi-homing. Gdy mobilnoķæ odbywa się za poķrednictwem interfejsu, bezproblemowe przekazanie moŋna ģatwo osiągnąæ, przeģączając ruch na wtórny interfejs przed przekazaniem, a następnie z powrotem do początkowego interfejsu. Inne projekty badawcze oparte na czystym podejķciu do mobilnoķci przeprowadzono w następujący sposób. Kontynuując projekt 4WARD, projekt Scalable and Adaptive Internet Solutions (SAIL) bada dostępny projekt przyszģej architektury Internetu i daje sposoby uģatwienia pģynnego przejķcia z obecnego Internetu, więc nie jest to w peģni tzw. podejķcie "czystej ģupki". Mobilnoķæ hosta zapewnia proponowany system NRS (Name Resolution System) do mapowania nazw obiektów na lokalizatory i utrzymywania informacji topologicznych dla hostów. Gdy występuje mobilnoķæ, MN aktualizuje swoje informacje topologiczne do lokalnego NRS w pobliŋu swojej lokalizacji. Projekt MOFI (Mobile ? Oriented Future Internet) [90], realizowany w Korei Poģudniowej, przyjmuje rozproszony system mapowania ID-LOC i proponuje globalną komunikację opartą na ID oraz lokalny routing oparty na LOC w domenie lokalnej. Proponuje takŋe pierwszy pakiet zapytaņ transmisji dla zoptymalizowanej komunikacji ķcieŋki. W Japonii projekt AKARI ma na celu wdroŋenie podstawowej technologii sieci nowej generacji do roku 2015. Gģówna zasada projektowania AKARI opiera się na oddzielnych strukturach fizycznych i logicznych w systemie adresowania do obsģugi mobilnoķci.
Kontrola jakoķci usģug
Tradycyjnie Internet traktuje caģy ruch w jednakowy sposób, czyli bez ŋadnej gwarancji QoS pod względem przepustowoķci, opóžnienia, jittera i utraty pakietów. Jednak niektóre aplikacje (np. Wideo i audio) mają bardziej rygorystyczne wymagania QoS niŋ inne (np. Dane). Dlatego gģównym celem kontroli QoS jest zdefiniowanie narzędzi i technik zapewniających przewidywalne, mierzalne i zróŋnicowane gwarancje jakoķci dla aplikacji w oparciu o ich charakterystykę i wymagania, zapewniając wystarczające zasoby (przepustowoķæ) i kontrolując opóžnienia pakietów, fluktuacje i parametry strat.
Dostarczanie zasobów sieciowych
Korelacje między ķcieŋkami komunikacji a wspóģdzieleniem zasobów narzuconym przez konwergencję sieci są gģównymi wyzwaniami, które naleŋy starannie uwzględniæ, aby wģączyæ QoS w Internecie. Mówi się, ŋe dwie ķcieŋki są skorelowane, gdy zdarzają się, ŋe dzielą co najmniej jeden interfejs wychodzący na węžle w sieci. Rysunek poniŋszy sģuŋy do uģatwienia zrozumienia tych problemów poprzez przedstawienie gģównej sieci dostawcy usģug internetowych (ISP) skģadającej się z trzech routerów wewnętrznych (IR), trzech routerów Egress (ER) i siedmiu rdzeni routerów (Cs).
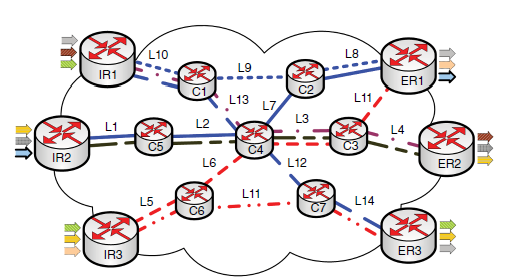
W tym przykģadzie ģącze L3 między C3 i C4 jest wspóģdzielone przez ķcieŋki 2, 5 i 6 (trzy skorelowane ķcieŋki), pochodzące z róŋnych węzģów wejķciowych, odpowiednio IR1, IR2 i IR3. Jako takie, strumienie ruchu, które mogą byæ mapowane do tych ķcieŋek, muszą mieæ trudnoķci z uzyskaniem zasobu (np. Przepustowoķci), którego potrzebują na wspóģdzielonym ģączu (linkach) / interfejsie (interfejsach) wzdģuŋ ķcieŋek. Z tego powodu rezerwacja zasobów i kontrola dostępu byģy badane od wielu lat jako podstawowe funkcje w projektach kontroli sieci, mające na celu umoŋliwienie Internetowi obsģugi QoS. IETF opracowaģ zintegrowane usģugi (IntServ) , architekturę kontroli QoS, aby zapewniæ kompleksową obsģugę QoS dla kaŋdej usģugi indywidualnie przez Internet. IntServ gwarantuje QoS dla kaŋdego przepģywu przez jawne rezerwowanie (np. Poprzez konfigurację programów planujących) iloķci zasobów wymaganych przez przepģyw w kaŋdym węžle na ķcieŋce, którą przepģyw będzie przenosiģ ze žródģa do miejsca przeznaczenia. Operacje zwykle opierają się na sygnalizacji RSVP (Resource Reservation Protocol), jak opisano szczegóģowo w odnoķniku. Ilekroæ ŋądanie usģugi jest odbierane w architekturze z obsģugą IntServ, sieæ jest najpierw sygnalizowana do sondowania (sondowania zdarzeņ) dostępnych zasobów. Następnie, w przypadku wystarczającej iloķci dostępnego zasobu, sieæ jest ponownie sygnalizowana, więc wymagany zasób jest zarezerwowany (zdarzenia rezerwacji), a stany powiązane są utrzymywane na wszystkich węzģach na odpowiedniej ķcieŋce komunikacyjnej. Ponadto rezerwacja jest zwalniana (zdarzenia zwalniające) po sygnalizacji, gdy odpowiednia sesja zakoņczy się. W ten sposób stany kontrolne i operacje sygnalizacyjne są wykonywane na zasadzie przepģywu, a podejķcie zostaģo powaŋnie skrytykowane z powodu braku skalowalnoķci. Jako alternatywa dla IntServ, IETF wprowadziģ usģugę Differentiated Service (DiffServ), jako standard architektury QoS oparty na klasie usģug (CoS) dla Internetu. W DiffServ, znanym równieŋ jako podejķcie agregacyjne, węzģy krawędziowe sieci lub stacje centralne (np. Brokerzy przepustowoķci) są zwykle uŋywane do utrzymywania stanów ruchu na przepģyw i klasyfikowania przepģywów do ograniczonej liczby CoS zgodnie z wczeķniej zdefiniowanymi zasadami, takimi jak, ale nie ogranicza się do QoS, protokoģów i typów aplikacji. Poniewaŋ przepģywy są klasyfikowane do CoS, węzģy rdzeņ / wnętrze mogą utrzymywaæ stany i przetwarzaæ je na CoS, a nie na przepģyw. Gģówną ideą jest przesunięcie zģoŋonoķci sterowania IntServ i obciąŋenia na krawędž sieci dla skalowalnoķci. Ponadto DiffServ implementuje statyczną rezerwację zasobów, przy czym kaŋdemu CoS w interfejsie przypisany jest staģy procent pojemnoķci interfejsu. Innymi sģowy, rezerwacje nie są regulowane dynamicznie w czasie dziaģania sieci. Narzut sygnalizacji RSVP zostaģ równieŋ usunięty z DiffServ. Chociaŋ rezerwacja zasobów statycznych jeszcze bardziej zwiększa skalowalnoķæ, nie optymalizuje wykorzystania sieci, poniewaŋ wymagania ruchu są dynamiczne i w większoķci nieprzewidywalne. W związku z tym rezerwację zasobów naleŋy przeprowadzaæ dynamicznie, uwzględniając bieŋące warunki zasobów sieci i zmieniające się wymagania ruchu, aby poprawiæ wykorzystanie zasobów. Z tego powodu dynamiczne mechanizmy kontroli QoS zostaģy przywrócone do DiffServ, jak opisano w dalszej częķci.
Ģączne udostępnianie zasobów
W spoģecznoķci badawczej argumentuje się, ŋe ģączne dostarczanie zasobów napędzane przez sygnalizację perflow w celu zwiększenia lub zwolnienia rezerwacji na CoS na kaŋde ŋądanie, tak jak w przypadku odniesienia, nie jest skalowalne z powodu nadmiernego narzutu sygnalizacji. W tym sensie IETF wprowadziģ standard protokoģu zbiorczej rezerwacji zasobów, rezerwację zasobu ponad rezerwę, aby umoŋliwiæ rezerwowanie większej iloķci zasobów niŋ rzeczywiste wymagania CoS, więc kilka zgģoszeņ serwisowych moŋe byæ przetwarzanych bez natychmiastowej sygnalizacji tak dģugo, jak poprzednia rezerwacja nadwyŋka jest wystarczająca do przyjęcia przychodzących ŋądaņ. W ten sposób zarówno stany kontroli QoS, jak i narzut sygnalizacji mogą zostaæ zredukowane ze względu na skalowalnoķæ. W tym rozdziale, nazywane równieŋ nadmiarowaniem zasobów, od wielu lat badano podejķcie jako obiecującą metodę osiągnięcia zróŋnicowanego QoS w sposób skalowalny. Jednak gģówne obawy dotyczą wpģywu marnotrawstwa zasobów, które moŋe wystąpiæ w przypadku nieefektywnej redystrybucji zasobów rezydualnych (nadmiernie zarezerwowanych, ale niewykorzystanych) wķród CoS. Pan i in. zaproponowano nadmierną rezerwę nadwyŋki przepustowoķci jako wielokrotnoķæ ustalonej liczby caģkowitej, a mianowicie "kwantyzacji", i opóžnienia zdarzeņ uwalniania zasobów w protokole rezerwacji Gateway Gateway (BGRP) dla przepģywów zagregowanych przeznaczonych do okreķlonej domeny - na podstawie Sink-Tree Protokóģ agregacji. To rozwiązanie nie jest zgodne z zachowaniami dynamicznymi ruchu, a zatem nie moŋe efektywnie wykorzystywaæ zasobów sieciowych. Sofia i in. zademonstrowaģ równieŋ wykorzystanie nadmiernej rezerwy zasobów w celu zmniejszenia narzutu sygnalizacji związanego z protokoģem SICAP (ang. Shared-segment-segment). Co waŋniejsze, autorzy przeanalizowali wpģyw systemów nadmiernej rezerwacji na marnotrawstwo zasobów w szerokim zakresie ustawieņ i porównaņ. Gģównym ograniczeniem tych podejķæ (np. BGRP i SICAP) jest brak wiedzy w czasie rzeczywistym na temat statystyk wykorzystania zasobów sieciowych, poniewaŋ polegają one na okresowych technikach sondowania ķcieŋki w celu uzyskania informacji o sieci. W konsekwencji rozwiązania te zapobiegają nadmiernemu rezerwowaniu zbyt duŋej nadwyŋki zasobów w celu zmniejszenia iloķci odpadów w cenie większych obciąŋeņ sygnalizacyjnych. Inne propozycje, takie jak prosty protokóģ sygnalizacji między domenami (SIDSP) i dynamiczna agregacja rezerwacji dla usģug internetowych (DARIS) równieŋ wykazaģy ograniczenia pod względem efektywnej redystrybucji zasobów rezydualnych. Pamiętając o wyzwaniach opisanych powyŋej, Zagregowana Alokacja Zasobów dla Wielu Uŋytkowników (MARA) wprowadza zestaw funkcji z dynamiczną redystrybucją zasobów rezydualnych wķród CoS wewnątrz sieci, próbując rozwiązaæ otwarte problemy. Niemniej jednak MARA opiera się równieŋ na okresowych i na ŋądanie technikach sondowania ķcieŋek i zapobiega rezerwowaniu zbyt duŋej nadwyŋki (podobnie jak w SICAP), co nie pozwala na optymalizację redukcji narzutu sygnalizacji, podczas gdy wciąŋ napotyka się niepoŋądane marnotrawstwo zasobów. Praca referencyjna proponuje rozwiązanie polegające na nadmiernym zasilaniu i sterowaniu ģadunkiem i równowagą, zwane QoS-RRC (Routing i kontrola zasobów), z wykorzystaniem protokoģów MARA. Oprócz centralnego serwera o nazwie Fabryka Ķcieŋek Ogólnych (GP) w rozwiązaniu QoS-RRC, kaŋdy router wejķciowy (np. IR) powinien samodzielnie decydowaæ i dostosowywaæ parametry nadmiaru zasobów niezaleŋnie od ģączy wspóģdzielonych przez wszystkie ingresy i nie ma mechanizmu wspóģpracy między routery wejķciowe. Jak wspomniano w pracy, chociaŋ agregacja QoS i Resource Over-Provisioning pozwalają na zmniejszenie nakģadów kontroli, jest to doķæ trudne, poniewaŋ nieefektywne rozwiązanie powoduje straty, podczas gdy liczba agregatów do utrzymania moŋe byæ bardzo duŋa w sieci z wieloma granicami routery jak na rysunku powyŋej. Badania i analizy tego kompromisu między redukcją narzutu sygnalizacji a marnotrawstwem zasobów moŋna znaležæ w odnoķniku. Ogólnie rzecz biorąc, im więcej zasobów jest nadmiernie zarezerwowanych, tym bardziej prawdopodobne jest zmniejszenie narzutu sygnalizacyjnego, ale z drugiej strony prowadzi do potencjalnie większych strat. W odniesieniu do tych wyzwaņ, ostatnie odkrycia, takie jak przepustowoķæ w oparciu o rezerwację klasy (COR), twierdzą, ŋe skuteczny mechanizm nadmiernej rezerwy zdecydowanie wymaga odpowiedniej: (i) architektury, aby skutecznie uwzględniaæ wzorce korelacji ķcieŋki komunikacyjnej i dynamikę ruchu na ķcieŋkach ; (iii) algorytmy do obliczania odpowiedniej szerokoķci pasma w celu zwiększenia rezerwy dla kaŋdego CoS, aby umoŋliwiæ optymalizację redukcji narzutu sygnalizacji; (iii) systemy wģaķciwego ponownego wykorzystania pozostaģej przepustowoķci w celu zminimalizowania wpģywu odpadów. Dlatego inteligentne udostępnianie zbiorczych zasobów jest bardzo potrzebne, aby skutecznie wspieraæ konwergencję usģug w Internecie 5G. Ma to kluczowe znaczenie ze względu na duŋą iloķæ danych, które będą zaangaŋowane w komunikację, heterogenicznoķæ charakterystyk ruchu i wymagania terminali uŋytkowników, a takŋe kontekst uŋytkowników, taki jak preferencje i lokalizacje. Aby pokazaæ dowód na wyŋszoķæ nadmiernej rezerwacji zasobów w stosunku do podejķæ przepģywowych pod względem skalowalnoķci, przeprowadziliķmy symulację przy uŋyciu topologii sieci przedstawionej na rysunku powyŋej i symulatora sieci (ns-2). Dla uproszczenia kaŋdy interfejs sieciowy zostaģ skonfigurowany z przepustowoķcią C = 1 Gbps i 4 CoS, na przykģad jednym kontrolnym CoS (dla pakietów kontrolnych), jednym przyspieszonym przekazywaniem (EF), jednym Assured Forwarding (AF) i jednym Best-? Effort (BE ), w ramach dyscypliny harmonogramowania Waŋona Fair Queuing (WFQ). Ponadto 20 000 ŋądaņ sesji naleŋących do trzech róŋnych typów ruchu, takich jak staģa szybkoķæ transmisji bitów (CBR), Pareto i wykģadniczy, zostaģo losowo wygenerowanych i zmapowanych do róŋnych CoS w oparciu o procesy Poissona. Ŋądania dotyczące przepustowoķci ruchu zostaģy wygenerowane przy uŋyciu równomiernego rozkģadu między 128 Kb / s a 8 Mb / s i zostaģy zmapowane na pary wejķcia-wyjķcia w oparciu o procesy Poissona. Aby pokazaæ bardziej stabilne wyniki, przeprowadziliķmy symulację pięæ razy z róŋnymi nasionami losowego mapowania ŋądaņ do CoS. Następnie wykreķlono ķrednie wartoķci dla wszystkich nasion z przedziaģem ufnoķci 95% (dalsze szczegóģy dotyczące konfiguracji symulacji są dostępne w odniesieniu). Rysunek powyŋej pokazuje, ŋe numery sondowania zasobów i zdarzenia rezerwacji nakģadają się, gdy sieæ jest mniej zatģoczona (numer ŋądania poniŋej 4000). Niemniej jednak liczba zdarzeņ sondowania przekracza rezerwację przepģywu, poniewaŋ liczba ŋądaņ wzrasta powyŋej 4000. Oznacza to, ŋe dostępnoķæ zasobów sieciowych zmniejsza się wraz ze wzrostem liczby aktywnych sesji w sieci, poniewaŋ niektóre ŋądania są odrzucane, gdy nie ma wystarczającej liczby zasób gwarantujący wymagane QoS. Po zakoņczeniu sesji uruchamiana jest odpowiednia sygnalizacja, aby zwolniæ powiązane rezerwacje do wykorzystania w przyszģoķci. Ogólny numer zdarzeņ sygnalizacyjnych dla podejķcia przepģywowego (sondowanie + rezerwacja + zwolnienie) jest równieŋ wykreķlony na rysunku. Poza wynikami na przepģyw, wydajnoķæ ponad rezerwacją jest takŋe wykreķlony. W związku z tym zauwaŋamy, ŋe skuteczna nadmierna rezerwacja moŋe potencjalnie zmniejszyæ liczbę sygnalizacyjną kontroli QoS, a tym samym związany z nią narzut przetwarzania. Co waŋniejsze, moŋna zauwaŋyæ, ŋe sygnalizacja sterująca nadmierną rezerwacją nie jest wyzwalana, gdy sieæ jest mniej zatģoczona, z liczbą ŋądaņ sesji poniŋej 4000. Rzeczywiķcie, kaŋdy CoS jest inicjalizowany z pewną iloķcią nadmiernej rezerwacji, a sygnalizacja jest wywoģywany tylko wtedy, gdy nadmiernie zarezerwowane parametry zasobów wymagają ponownego dostosowania, aby zapobiec gģodowaniu CoS. Zasadniczo nadmierna rezerwacja pozwala na ograniczenie zdarzeņ sygnalizacyjnych powyŋej 90% w przypadku podejķcia "przepģywowego", w zaleŋnoķci od poziomu przeciąŋenia sieci.
Pojawiające się podejķcie do nadmiernego udostępniania zasobów
Celem tej sekcji jest opisanie ogólnego mechanizmu, który jest w stanie zintegrowaæ SDN i NFV w celu efektywnej kontroli nad rezerwacją zasobów w celu obsģugi zróŋnicowanego QoS przez Internet 5G bez zbędnej sygnalizacji i związanych z tym kosztów przetwarzania (np. Wymagania procesora, pamięci i energii) lub marnotrawstwo zasobów. W celu uģatwienia zrozumienia. Rysunek poniŋej przedstawia scenariusz sieci wielu operatorów obejmujący operatora sieci I, operatora sieci II i inne sieci, wszystkie uwaŋane za chmurę chmur.
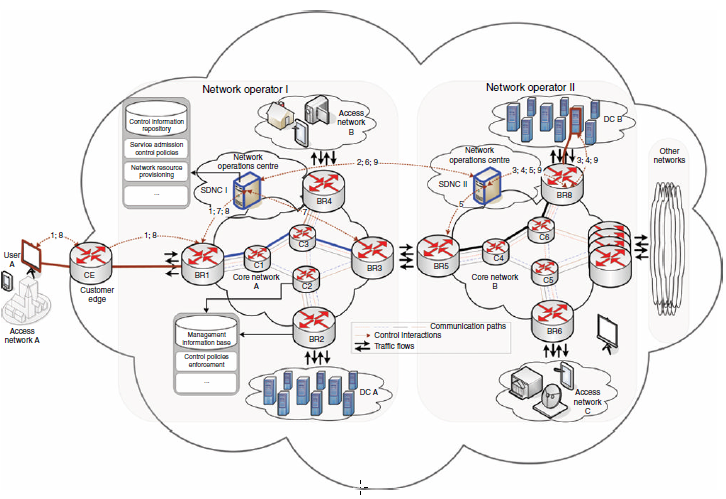
Kaŋda sieæ stanowi sieæ rdzeniową, do której doģączone są róŋne sieci dostawców dostępu i usģug. Na przykģad w sieci operatora I sieæ rdzeniowa A jest podģączona do sieci dostępowych A (za poķrednictwem routera Customer Edge (CE)), sieci dostępowej B i DC A. Poniewaŋ jest to szczegóģowo opisane w referencjach, technologie wirtualizacji mogą byæ zastosowane w kontrolerach domeny, aby umoŋliwiæ wielu dzierŋawcom wspóģuŋytkowanie tej samej fizycznej infrastruktury DC. Umoŋliwia takŋe wspóģdzielenie infrastruktury sieciowej z dostępem do rdzenia / sieci szkieletowej i DC. Ponadto ogólna kontrola w sieci kaŋdego operatora jest regulowana za pomocą SDNC znajdującego się w centrum operacji sieciowych. W szczególnoķci SDNC jest odpowiedzialny za udzielanie lub odmawianie dostępu do sieci i powiązanych zasobów w taki sposób, aby zapewniæ, ŋe kaŋdy dopuszczony uŋytkownik otrzyma zakontraktowane QoS. Funkcje SDNC obejmują między innymi równowaŋenie obciąŋenia ruchem, aby uniknąæ niepotrzebnego występowania przeciąŋenia w sieci, podczas gdy poģączenia między domenami są wykonywane zgodnie z wczeķniej zdefiniowanymi umowami o poziomie usģug (SLA) między operatorami ze względu na skalowalnoķæ. W tym celu SDNC jest wģączony do definiowania odpowiednich zasad sterowania i dyktowania egzekwowania elementów transportowych (np. Przeģączników i routerów) za pomocą odpowiednich protokoģów sygnalizacyjnych (np. Protokoģu zgodnego z OpenFlow). Dzięki temu kaŋda aplikacja zostanie skutecznie powstrzymana przed gģodem innych aplikacji swoich zasobów w sieci. Wģączenie tych funkcji wymaga, aby SDNC utrzymywaģ dobrą znajomoķæ topologii sieci i powiązanych statystyk zasobów ģącza w czasie rzeczywistym w celu ukierunkowania na efektywną wydajnoķæ. Dlatego SDNC osadza zestaw komponentów kontrolnych, takich jak, ale nie ograniczając się do: (i) Repozytorium informacji kontrolnych (CIR) jako bazy danych do przechowywania informacji topologicznych sieci i profili uŋytkowników; (ii) Zasady kontroli dostępu do usģug (SACP), jako podmiot odpowiedzialny za definiowanie odpowiednich zasad kontroli i zarządzanie dostępem do zasobów sieciowych; oraz (iii) Network Resource Provisioning (NRP), który moŋna wykorzystaæ do zaawansowanej alokacji zasobów. Dalsze szczegóģy na temat tych komponentów pod względem funkcji i interakcji znajdują się w następnych sekcjach
Repozytorium informacji sterujących
CIR jest wykorzystywany przez SDNC do utrzymania topologii sieci i powiązanych statystyk zasobów ģącza, w tym ķcieŋek komunikacyjnych, które mogą byæ tworzone w sieci wraz z identyfikatorami wychodzących interfejsów, które naleŋą do ķcieŋek. Topologia sieci i ķcieŋki mogą byæ wstępnie zdefiniowane lub dynamicznie wykrywane lub obliczane w sposób referencyjny. Co więcej, CIR rejestruje caģkowitą pojemnoķæ kaŋdego interfejsu sieciowego i iloķæ zarezerwowanej przepustowoķci i wykorzystywanej w kaŋdym CoS w interfejsie. Ponadto sesje uŋytkowników mapowane na CoS skonfigurowane w sieci są utrzymywane wraz z powiązanymi informacjami. Informacje o sesji aktywnej obejmują między innymi wymagania QoS sesji (np. Przepustowoķæ, opóžnienie, jitter i utrata pakietów), identyfikator sesji, identyfikatory przepģywów skģadających się na sesję, identyfikator CoS do do której naleŋy sesja, identyfikatory žródģowe i docelowe przepģywów (np. IP i Media Access Control - adresy MAC -) oraz identyfikatory portów. Inne informacje o profilu uŋytkownika, takie jak parametry rozliczeniowe i personalizacyjne, mogą byæ równieŋ przechowywane w CIR. Podsumowując, specyficzna konstrukcja i konfiguracje SDNC zaleŋaģyby od preferencji operatorów, które mogą się róŋniæ w zaleŋnoķci od operatora.
Zasady kontroli dostępu do usģugi
SACP umoŋliwia SDNC dopuszczenie lub odmówienie dostępu do usģugi sieci poprzez dynamiczne uwzględnienie wymagaņ QoS ŋądania usģugi przychodzącej (np. Przepustowoķci) i dostępnoķci zasobów sieciowych moŋliwych do uzyskania z lokalnej bazy danych CIR. Zapewnia interfejs umoŋliwiający interakcje z uŋytkownikami koņcowymi w celu odbierania ŋądaņ z jednej strony, a takŋe z węzģami sieci (np. Routerami) w celu wysyģania instrukcji sterujących, które mają byæ egzekwowane w caģej sieci, z drugiej strony. Stąd, po przyjęciu, zakoņczeniu lub ponownym dostosowaniu wymagaņ QoS sesji w CoS na ķcieŋce komunikacyjnej, informacje związane z sesją (np. Wykorzystanie zasobów) muszą byæ aktualizowane w lokalnym CIR w czasie rzeczywistym. W sytuacji, w której nadmierna rezerwacja zasobów jest realizowana w sposób referencyjny, SACP jest w stanie przyjmowaæ, koņczyæ lub dostosowywaæ wymagania QoS bez nadmiernego narzutu sygnalizacji lub marnotrawstwa zasobów. Od statystyki sieci wykorzystania zasobów są utrzymywane w czasie rzeczywistym w CIR, informacje mogą byæ wykorzystane do poprawy funkcji równowaŋenia obciąŋenia ruchu w elastyczny sposób bez niepoŋądanego sondowania ķcieŋki i związanego z tym narzutu sygnalizacji. Jednak zawsze, gdy nadmierna rezerwacja ŋądanego CoS zostanie wyczerpana, komponent KPR musi zostaæ uruchomiony, aby prawidģowo obliczyæ nowe parametry rezerwacji w celu ich ponownego dostosowania w ramach CoS na odpowiedniej ķcieŋce. W ten sposób zasoby rezydualne mogą byæ dynamicznie ponownie wykorzystywane, aby zapobiec marnotrawstwu, jak szczegóģowo opisano w następnej częķci.
Dostarczanie zasobów sieciowych
Gģówną rolą komponentu KPR jest okreķlenie iloķci zasobów, które mają byæ rezerwowane, oraz parametrów, takich jak progi rezerwacji, które naleŋy skonfigurowaæ dla kaŋdego CoS na kaŋdym interfejsie w sieci zgodnie z lokalnymi zasadami kontroli. Komponent ten musi byæ wystarczająco inteligentny, aby umoŋliwiæ integrację istniejących algorytmów i zasad rezerwacji poza rezerwacją, tak jak w referencjach, w tym przyszģych algorytmów. Jest to waŋne, poniewaŋ NRP jest wywoģywany dynamicznie przez funkcje kontroli dostępu, tak ŋe parametry rezerwacji mogą byæ ponownie dostosowane na potrzeby zapobiegania nieefektywnemu wykorzystaniu zasobów przy jednoczesnym zmniejszeniu częstotliwoķci sygnalizacji. Okazuje się, ŋe ten komponent moŋe byæ równieŋ uŋywany do tworzenia i zarządzania deterministycznymi ķcieŋkami komunikacji wewnątrz sieci (np. Ķcieŋki przeģączania etykiet, jak w Multi-protocol Label Switching - MPLS). Dlatego teŋ, gdy NRP pomyķlnie obliczą nowe parametry rezerwacji, SDNC powinien przekazaæ nowe wymagania konfiguracyjne do danych węzģów na odpowiednich ķcieŋkach egzekwowania. Zasady kontroli są wymuszane na węzģach za pomocą komponentu CPE (Control Policies Enforcement), który jest szczegóģowo opisany w następnej podsekcji.
Funkcje egzekwowania sterowania
Kaŋdy węzeģ sieci (np. routery) implementuje zestaw komponentów, podstawowych funkcji sterowania wymaganych we wszystkich węzģach sieci w celu wykonania instrukcji sterujących, które mogą byæ odbierane z SDNC. Te funkcje obejmują między innymi bazę informacji zarządzania (MIB) i komponenty CPE. Baza MIB oznacza wszystkie starsze bazy danych kontroli, zazwyczaj dostępne we wszystkich węzģach sieci, tj. Bazę informacji o routingu (RIB), bazę informacji o routingu multiemisji (MRIB) oraz bazę informacji o przekazywaniu (FIB) i tabelę OpenFlow. Ponadto CPE wykorzystuje podstawowe funkcje transportowe, aby umoŋliwiæ rozpoznawanie portów UDP (routery stale nasģuchują na okreķlonym porcie UDP) lub opcję routera IP (RAO) w węzģach, aby poprawnie przechwytywaæ, interpretowaæ i przetwarzaæ komunikaty sterujące. CPE jest odpowiedzialny za interakcję z funkcjami zarządzania zasobami (RMF) w celu prawidģowego skonfigurowania programów planujących w węzģach, zapewniając tym samym, ŋe kaŋdy CoS otrzymuje przydzieloną szerokoķæ pasma. Ponadto ģączy się z MIB i starszymi protokoģami (np. Protokoģami routingu i protokoģami zarządzania) na węzģach, aby ponownie wykorzystaæ istniejące i przyszģe funkcje sieciowe. CPE moŋna równieŋ wykorzystaæ do wymuszenia deterministycznych ķcieŋek przy uŋyciu etykiety MPLS lub kanaģu multiemisji na podstawie instrukcji SDNC. Pomaga takŋe SDNC, wypeģniając komunikaty kontrolne odpowiednimi informacjami, umoŋliwiając na przykģad gromadzenie identyfikatorów wychodzących interfejsów i ich pojemnoķci jako obiektu trasy zapisu (RRO) na ķcieŋkach. Gdy CPE jest wdroŋony na granicy sieci, zawiera dodatkowe funkcje do operacji przesyģania i routingu między domenami, które mogą byæ oparte na danych wejķciowych z tradycyjnego BGP. Kontrola ruchu i warunkowanie ruchu (np. Ksztaģtowanie ruchu i nadzorowanie ruchu) muszą byæ równieŋ zapewnione na granicy sieci, aby wymusiæ, aby dopuszczone strumienie ruchu byģy zgodne z umowami SLA.
Konfiguracje sieciowe
SDNC jest w stanie dynamicznie odkrywaæ topologię sieci w miarę uruchamiania nowych węzģów w sieci. Moŋna uŋyæ istniejących mechanizmów wykrywania topologii, importując informacje z protokoģów routingu w stanie ģącza. Stąd, przyjmując topologię sieci i odpowiedni algorytm (np. Dijkstra) jako dane wejķciowe, SDNC jest w stanie obliczyæ wszystkie moŋliwe ķcieŋki, zwģaszcza ķcieŋki "od krawędzi do krawędzi" wewnątrz sieci rdzeniowej pod jej kontrolą. Poģączenie ķcieŋek moŋe prowadziæ do wszystkich moŋliwych rozgaģęzionych tras, jak w przypadku odniesienia, a najlepsze ķcieŋki mogą byæ filtrowane, na przykģad w oparciu o liczbę przeskoków lub przepustowoķci wąskiego gardģa. Warto przypomnieæ, ŋe wykorzystanie deterministycznych ķcieŋek jest bardzo waŋne dla poprawy kontroli zasobów sieciowych. W naszym przypadku uŋycia, deterministyczną ķcieŋkę moŋna uzyskaæ za pomocą etykiety MPLS lub przypisując unikalny kanaģ multiemisji (S, G). W tym scenariuszu S (žródģo) moŋe byæ adresem IP wejķciowego routera granicznego (BR), z którego pochodzi ķcieŋka, a G (grupa) moŋe byæ adresem multiemisji. Po obliczeniu przez SDNC ķcieŋki i początkowych parametrów nadmiernej rezerwacji dla kaŋdego interfejsu na ķcieŋce, hermetyzuje informacje w komunikacie sterującym i wysyģa je do wszystkich węzģów na ķcieŋce. Poniewaŋ komunikat kontrolny przemieszcza się wzdģuŋ ķcieŋki, kaŋdy odwiedzany węzeģ przechwytuje wiadomoķæ i odpowiednio konfiguruje swoje lokalne interfejsy (np. Tabele OpenFlow, tabele przekazywania / routingu i parametry rezerwacji ponad zasobami).
2.6.6 Operacje sieciowe
Operacje sieci na rysunku powyŋej są zilustrowane, przy uŋyciu wykresu sekwencji na rysunku
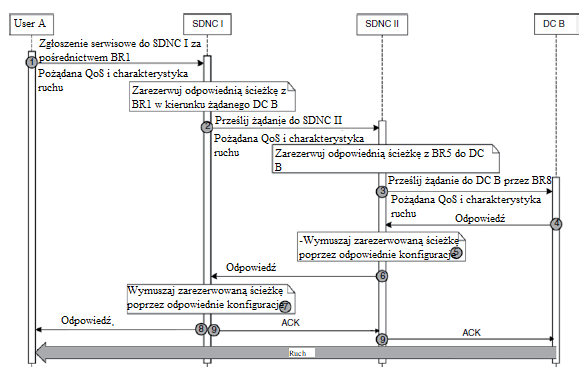
Ponadto podkreķlono korzyķci, jakie poģączenie SDN i nadmiernej rezerwy zasobów moŋe wnieķæ do Internetu 5G. W związku z tym, gdy sieæ jest inicjalizowana i ustawiana do uruchamiania, kaŋde ŋądanie usģugi musi byæ przetwarzane przez SDNC. Ma to na celu wykonywanie funkcji, ale nie wyģącznie, uwierzytelniania usģug, autoryzacji i rozliczania (AAA), QoS i kontroli dostępu w celu odróŋnienia kontroli i umoŋliwienia optymalnego wykorzystania zasobów sieciowych. Stąd ŋądanie usģugi powinno okreķlaæ poŋądaną QoS (np. Przepustowoķæ, opóžnienie, jitter, utratę pakietów i bufor), preferencje personalizacji usģugi i związane z nią charakterystyki ruchu (np. Žródģowy i docelowy adres IP i porty, obsģugiwane kodeki itp.) . Ta informacja ma zasadnicze znaczenie dla wģaķciwej negocjacji sesji, gdzie transakcje sterujące mogą byæ obsģugiwane za pomocą protokoģu inicjowania sesji - SIP lub dowolnego innego protokoģu sygnalizacji (np. Protokoģu zgodnego z sygnalizacją następnego kroku (NSIS)) okreķlonego przez operatora. Naleŋy zauwaŋyæ, ŋe ŋądanie usģugi moŋe byæ równieŋ wyzwalane przez SDNC, w zaleŋnoķci od trybów operacji specyficznych dla usģug i sieci, to znaczy albo trybu ķciągania (od strony uŋytkownika koņcowego), albo trybu push (od strony sieci). Aby uģatwiæ zrozumienie, zaģóŋmy, ŋe uŋytkownik A chce korzystaæ z usģugi wideo 3D od dostawcy DC B (centrum danych B) w chmurze. W związku z tym uŋytkownik wydaje ŋądanie usģugi, które jest kierowane do SDNC przez bramę BR1 (krok 1). Ŋądanie usģugi zawiera wymagania QoS uŋytkownika (np. Przepustowoķæ) i związane z nim charakterystyki ruchu (np. Kodek). W związku z tym, w oparciu o otrzymane informacje, SDNC I wykonuje kontrolę dostępu zgodnie ze wstępnie zdefiniowanymi lokalnymi zasadami sterowania i księguje najlepszą ķcieŋkę z wystarczającą dostępną szerokoķcią pasma do poģączenia bramy BR1 i wyjķcia BR3 w kierunku DC B. Jest zatem bardzo waŋne, aby zauwaŋ, ŋe SDNC jest w stanie to zrobiæ bez sondowania ķcieŋki lub dodatkowej sygnalizacji QoS do sieci, poniewaŋ zakģadamy, ŋe integruje ona rozwiązanie rezerwowania zasobów opisane w odnoķniku. W przypadku powodzenia tych operacji serwer przekierowuje ŋądanie do SDNC II (sieæ operatora B), jako kolejną domenę na koņcowej ķcieŋce do DC B. Gdy SDNC II odbiera ŋądanie, rezerwuje równieŋ najlepsza ķcieŋka (BR5 do BR8) bez dodatkowego narzutu sygnalizacji i sprawdza dostępnoķæ ŋądanej usģugi w DC B. Następnie, po otrzymaniu pomyķlnej odpowiedzi z DC B, SDNC II wymusza zarezerwowaną ķcieŋkę poprzez prawidģowe skonfigurowanie routerów granicznych na ķcieŋce (BR5 i BR8). Przykģady konfiguracji obejmują grupę multiemisji wybranej ķcieŋki (w domenie z obsģugą multiemisji) lub etykietę MPLS (w domenie MPLS) i parametry warunkujące ruch (np. Klasyfikacja, ksztaģtowanie i nadzorowanie). Zapewni to, ŋe przychodzące pakiety multimedialne zostaną poprawnie zamknięte w routerach krawędziowych wejķciowych, aby podąŋaæ poŋądanymi ķcieŋkami, więc będą cieszyæ się zarezerwowanym dla nich QoS. Pakiety są dekapulowane na odpowiednich routerach krawędziowych wyjķciowych w celu dostarczenia do uŋytkownika koņcowego lub następującej domeny. Jak wyjaķniliķmy wczeķniej, tylko BR są skonfigurowane, poniewaŋ zakģada się, ŋe rezerwowane zasoby są nadal dostępne na węzģach rdzeņ / wnętrze ķcieŋki. Jak szczegóģowo omówiliķmy wczeķniej, węzģy rdzeniowe są sygnalizowane w celu rekonfiguracji parametrów rezerwacji dopiero po wyczerpaniu rezerwowanego zasobu i nie są wystarczające dla przychodzącego ŋądania. W ten sposób moŋna nie tylko znacznie zmniejszyæ częstotliwoķæ sygnalizacji, ale równieŋ skróciæ czas konfiguracji sesji. Następnie SDNC II odpowiada na SDNC I, a takŋe wymusza ķcieŋkę zarezerwowaną dla usģugi (patrz krok 7). Wreszcie SDNC I powiadamia uŋytkownika A o sukcesie operacji (patrz krok 8). W tym samym czasie SDNC I wysyģa komunikat potwierdzenia (ACK) do SDNC II, którego wiadomoķæ jest przekazywana do DC B (patrz krok 9) w celu wyzwolenia noķnika streaming. W rezultacie ķcieŋka koniec-koniec jest budowana w sposób skalowalny jako konkatenacja ķcieŋek podrzędnych ķwiadomych przepustowoķci zbudowanych niezaleŋnie w domenach na ķcieŋce. Ma to ogromne znaczenie, aby umoŋliwiæ kaŋdemu operatorowi wdroŋenie wģasnego protokoģu kontroli. Jeķli chodzi o kontrolę ģącznoķci w sieciach dostępowych przedstawionych w tej sekcji, zakģada się, ŋe kaŋda sieæ dostępowa lub DC jest doģączona do sieci rdzeniowej za pomocą odpowiedniej ķcieŋki pasma zgodnie z umowami SLA między uŋytkownikami koņcowymi a dostawcami usģug.
Podsumowanie
Waŋnym aspektem jest okreķlenie ram i procedur, które mogą obejmowaæ ogromną liczbę heterogenicznych urządzeņ podģączanych do Internetu za poķrednictwem niezliczonej liczby technologii przewodowych i bezprzewodowych. Aspekty ģącznoķci muszą byæ nie tylko ulepszone, aby umoŋliwiæ i zoptymalizowaæ sposób obsģugi tych poģączeņ, biorąc pod uwagę specyfikę kaŋdej dostępnej technologii dostępu, ale takŋe sposób, w jaki urządzenia te są poģączone przez usģugi (i interfejs) (np. Aplikacje sensoryczne linkowanie do czujników) musi byæ uogólnione. W ten sposób obecne architektury i ramy przechodzą od ograniczonego wdroŋenia wertykalnego do bardziej elastycznego wdroŋenia poziomego, pozwalając na wdraŋanie ich w róŋnych obszarach i przypadkach uŋycia, zgodnie z podejķciem "zbuduj, uŋywaj wielokrotnie, wielokrotnie". Ponadto zģoŋonoķæ wymuszana nowatorskimi scenariuszami musi uwzględniaæ dynamikę dziaģania sieci, która obecnie przeksztaģca się w piekģo Capex i Opex dla operatorów i dostawców usģug. W tym sensie technologie wspomagające, takie jak SDN, umoŋliwiają dziaģanie sieci kontrolowane w sposób wydajny i dynamiczny, pozwalając sieci reagowaæ na zmiany w sieci, jak równieŋ wzmacniając nowatorskie scenariusze eksperymentalne z moŋliwoķcią odróŋnienia ruchu eksperymentalnego od sieci produkcyjnych. Co więcej, takie koncepcje mogą byæ dodatkowo wzmocnione poprzez ich integrację z aspektami wirtualizacji. W ten sposób podstawowa fizyczna sieæ i tkanina przetwarzania operatora mogą byæ formowane na ŋądanie w sieci logiczne i przetwarzaæ węzģy emulujące róŋne funkcje sieciowe w funkcji wirtualizacji funkcji sieciowych. W związku z tym operatorzy mogą ģatwo i dynamicznie korzystaæ z zasobów sieciowych i przetwarzania oraz ģatwo wdraŋaæ nowe procedury sieciowe, gdy sieæ zmienia się i / lub roķnie. W tym trudnym ķrodowisku przewidzianym na przyszģoķæ Internet nie moŋe zagwarantowaæ uŋytkownikom jakoķci usģug w zakresie heterogenicznoķci, o ile nie jest wspomagana przez odpowiednie mechanizmy adaptacyjne, które mogą dostosowaæ róŋnorodne wymagania aplikacji do obecnych warunków sieciowych. Uwaŋa się, ŋe pojawienie się SDN i NFV zapewni elastycznoķæ i inteligencję w projekcie sterowania, aby umoŋliwiæ ģatwą parametryzację sieci i aplikacji na ŋądanie w taki sposób, aby oferowaæ zwiększona satysfakcja uŋytkowników i osiągnięcie efektywnego wykorzystania zasobów sieciowych. Jednak ta koncepcja ķwiadomoķci zasobów wymusza stosowanie sygnalizacji sterującej i technik utrzymania stanu, które wymagają skalowalnych rozwiązaņ, aby zapewniæ dobrą wydajnoķæ dla szybkiej konfiguracji sesji i efektywnego zuŋycia procesora, pamięci i energii. Chociaŋ nadmierna rezerwacja zasobów sieciowych wydaje się najbardziej obiecującym podejķciem w tym kontekķcie, wymaga wiedzy w czasie rzeczywistym na temat topologicznych informacji sieciowych i powiązanych statystyk zasobów ģącza w celu rozwiązania problemu kompromisu między skalowalnoķcią (redukcja narzutów sterowania) a efektywnym wykorzystaniem zasobów. Dlatego teŋ dalsze dochodzenia nadal uwaŋane są za konieczne. Mamy nadzieję, ŋe ten rozdziaģ przyczyni się do zrozumienia trendów w rozwoju i wyzwaņ stojących przed sieciami nowej generacji i utoruje drogę do dalszych innowacji na tej szybko rozwijającej się arenie, aby dostarczyæ Internet 5G.