
Ha(c)ki na… HTML 5
HTML5 to nowy termin "Sieć". Podobnie jak wcześniej Ajax i Web 2.0, termin ten może powodować zamieszanie, gdy jest używany w różnych kontekstach. HTML5 jest technicznie piątą wersją języka znaczników HTML, ale termin ten jest używany do opisania szeregu specyfikacji technologii sieciowych nowej generacji, które obejmują interfejsy API CSS3, SVG i JavaScript. Aby zrozumieć HTML5 w tym kontekście, najpierw należy zrozumieć, że HTML5 nie jest jedną technologią stosowaną lub dodaną do aplikacji internetowej. Istnieje ponad 30 specyfikacji w ramach parasola HTML5, a każda z nich jest na innym etapie dojrzałości. Ponadto każda specyfikacja znajduje się w innym stanie przyjęcia i, potencjalnie, wdrożenia, przez głównych producentów przeglądarek. W zależności od wymagań biznesowych aplikacji twórca aplikacji wybierze funkcje HTML5, z których może skorzystać. Jest całkowicie możliwe, że tylko kilka dostępnych specyfikacji zostanie wykorzystanych do ostatecznego wdrożenia nowoczesnej aplikacji internetowej. Krytycy często twierdzą, że zanim zaczniesz używać go w swojej aplikacji, musisz poczekać, aż HTML5 będzie w 100% obsługiwany. To po prostu nieprawda. Wiele specyfikacji osiągnęło już dojrzałość i jest w pełni zaimplementowanych przez nowoczesne przeglądarki. Inne specyfikacje są na wczesnym etapie rozwoju lub są słabo obsługiwane przez niektórych głównych producentów przeglądarek. Ważne jest, aby wiedzieć, jakiego typu specyfikacji używasz. Badania są pomocne, ale jedynym prawdziwym sposobem na to jest dokładne przetestowanie aplikacji we wszystkich przeglądarkach. W przypadku specyfikacji, które są nowsze lub nie są tak mocno obsługiwane, niektórzy sprytni programiści stworzyli darmowy i otwarty kod źródłowy, który można wykorzystać do shimowania lub polyfill w starszych przeglądarkach. Jak zdefiniował Remy Sharp, "Wielokrotne polyfill lub polyfiller jest fragmentem kodu (lub wtyczki), który zapewnia technologię, którą Ty, deweloper, oczekujesz od przeglądarki w sposób natywny. Spłaszczanie interfejsu API, jeśli chcesz. "Naszym zdaniem najlepszym polifillem jest taki, który pozwala pisać kod tak, gdyby funkcja była natywnie obsługiwana, i działa w tle, gdy jest to konieczne, zachowując przejrzystość zarówno dla użytkownika, jak i programisty. W większości przypadków każda specyfikacja HTML5 zawiera polyfill lub wiele konkurujących ze sobą wypełniaczy i jest gotowa do użycia już dziś. Tu znajdziesz odniesienia do niektórych z najbardziej skutecznych polyfilli w Internecie.
Hack No.1
Dlaczego HTML5?
Początkujący programista może zapytać: "Dlaczego powinienem dbać o HTML5?".Niestety nie ma prostej odpowiedzi na to pytanie. Nawet najbardziej zaawansowani twórcy stron internetowych odpowiedzą na to pytanie w różny sposób, w zależności od funkcji, które są im najbardziej znane. Ale ogólnie rzecz biorąc, istnieją pewne wspólne trendy, które obejmują zestaw funkcji i na które zgodzi się większość programistów. Przed HTML5 Internet nie był uważany za rywala w stosunku do natywnych aplikacji komputerowych i mobilnych. Niemal od samego początku sieć została uznana za łatwe do wdrożenia rozwiązanie wieloplatformowe. Zostało to jednak utrudnione z powodu braku bardzo ważnych wymagań biznesowych: wydajności, bezpieczeństwa i grafiki. Teoria jest taka, że jeśli nowoczesna przeglądarka internetowa mogłaby dojrzeć jako platforma aplikacji, programiści mogliby przestać tworzyć natywne aplikacje specyficzne dla platformy. Rewolucja Ajax poprowadziła świat aplikacji internetowych we właściwym kierunku, zapewniając asynchroniczne aktualizacje w tle serwera za pośrednictwem obiektu XMLHttpRequest, formatu przesyłania JSON i eksplozji bibliotek JavaScript, które rozciągnęły granice rozwoju aplikacji w przeglądarce, z których wiele nadal stanowią podstawę dla obsługi wypełniania wielopunktowego. Jednak HTML5 dotyczy nowoczesnej przeglądarki zapewniającej niezbędne wsparcie, umożliwiające natywne tworzenie zaawansowanych aplikacji. Aby to osiągnąć, funkcje takie jak możliwość utrzymania historii przeglądarki i dodawania zakładek podczas interakcji asynchronicznych, komunikacja między domenami, lokalna pamięć masowa, obsługa offline, bogata grafika, a nawet nowe protokoły w celu poprawy szybkości i wydajności warstwy łączności nadal trzeba było stworzyć i ulepszyć. Prefiksy przeglądarki są najczęściej spotykane w CSS.
Implementacje HTML5
Ponieważ chętny programista jest gotowy do kontynuowania wdrażania niektórych nowych funkcji dostępnych w tym tekście, ważne będzie, aby zrozumieć, że wiele specyfikacji HTML5 jest w fazie eksperymentalnej. Jednym z głównych wyzwań podczas pisania książki o zmieniających się specyfikacjach jest utrzymanie aktualności i aktualności informacji. Poniższe tematy są ważnymi zagadnieniami podczas uczenia się eksperymentalnych specyfikacji przeglądarki internetowej.
Prefiksy specyficzne dla przeglądarki
Aby twórcy przeglądarek mogli wdrożyć eksperymentalne funkcje (zwykle implementujące specyfikacje przed ich ukończeniem), twórcy przeglądarek "prefiks" tę funkcję dodają skrótem, który ogranicza jej użycie do każdej konkretnej przeglądarki. Świetnym przykładem tego jest implementacja requestAnimationFrame, czyli metody JavaScript na stronie, która pomaga w animacji w przeglądarce. Każda przeglądarka pierwotnie implementowała tę funkcję z następującymi prefiksami:
requestAnimationFrame
webkitRequestAnimationFrame
mozRequestAnimationFrame
oRequestAnimationFrame
msRequestAnimationFrame
Walidacja za pomocą HTML5 Conformance Checker
Walidator HTML to oprogramowanie, które analizuje strony internetowe w stosunku do zestawu standardów internetowych określonych przez określoną definicję typu dokumentu (DTD). Jeśli nie znasz DTD, pomyśl o nim jako o metadanych poprzedzających znaczniki HTML, aby poinstruować przeglądarkę, jakiego "smaku" HTML będziesz używać. Walidator HTML zwraca listę znalezionych błędów, zgodnie z wybranymi standardami. Do naszych celów założymy, że korzystamy z definicji typu dokumentu HTML5. Definicja typu dokumentu HTML5 jest bardziej łagodna niż najnowsza definicja XHMTL, a wyniki nowego walidatora W3C odzwierciedlają tę różnicę. W końcu walidator nie powinien zgłaszać wyjątków w kwestiach stylistycznych. Powinien koncentrować się na sprawdzaniu poprawności kodu HTML względem specyfikacji.
HTML5 Lint oznacza to, że programiści powinni być również gotowi do korzystania z narzędzia lint w celu ujawnienia problemów stylistycznych w swoim kodzie. Niektóre z najczęstszych problemów, które należy sprawdzić, to spójne wcięcie, małe litery i pominięcie tagów zamykających. W chwili pisania tego tekstu zalecamy narzędzie HTML5 Lint.
Referencje dotyczące statusów implementacji HTML5 i obsługi funkcji
Będziemy nadal aktualizować przykłady zamieszczone w tym tekście tak często, jak to możliwe. Istnieje również wiele wspaniałych zasobów w Internecie, aby odwoływać się do statusów implementacji HTML5 i obsługiwać określone przeglądarki.
Dla wszystkich nowoczesnych przeglądarek:
http://caniuse.com/
http://html5test.com/
W przypadku Chrome:
http://www.chromium.org/developers/web-platform-status
W przeglądarce Internet Explorer:
http://msdn.microsoft.com/en-US/ie/ff468705.aspx
W przeglądarce Mozilla Firefox:
https://wiki.mozilla.org/Features
W przypadku Apple Safari:
https://developer.apple.com/technologies/safari/html5.html0
Hack No.2
Termin "haker" ma negatywne znaczenie w mediach, ale ewoluował, aby opisać wiele różnych osób technicznych. Wikipedia zawiera trzy bardzo różne definicje terminu haker:
1. Haker (bezpieczeństwo komputerowe), ktoś, kto uzyskuje dostęp do systemu komputerowego, obchodząc jego system bezpieczeństwa
2. Haker (hobbysta), który dokonuje innowacyjnych dostosowań lub kombinacji detalicznego sprzętu elektronicznego i komputerowego
3. Hacker (subkultura programistów), który podziela antyautorytarne podejście do tworzenia oprogramowania związane z ruchem wolnego oprogramowania
W kontekście definicji 2 używamy terminu hack. Wśród tych typów hacków termin odnosi się do niezależnego dowodu koncepcji, podobnego do zwinnych skoków lub przepisów. Te szybkie rozwiązania sprawdzają lub weryfikują interfejs API, funkcję lub technologię, a także mogą odgrywać bardzo ważną rolę, nie tylko w kształceniu zespołu programistów, ale także w kierowaniu kierunkiem rozwoju w cyklu życia projektu.
Sekcja 1: Hakowanie w sposób semantyczny
Duch HTML5 to prostota. HTML5 ułatwia wdrażanie standardów sieciowych, które w przeszłości były trudne do wdrożenia. Zamiast próbować wynaleźć Internet, wizjonerskie konsorcja, takie jak WHATWG (grupa robocza ds. technologii hipertekstowej) i W3C (konsorcjum World Wide Web) spojrzały na standardy sieciowe, które ewoluowały i na nich bazowały. Zasadniczo HTML5 jest przede wszystkim aktualizacją języka HyperText Markup Language (HTML). W tej sekcji zaczniemy od podstawowych elementów składowych HTML, elementów semantycznych, aby zapewnić podstawy dla prostych, ale potężnych nowych technologii przeglądarki internetowej. Otwórz więc swój ulubiony edytor kodów, zaparz dzbanek kawy i przygotuj się na kodowanie w najpotężniejszym języku, jaki kiedykolwiek widział Internet: HTML5!
HACK No.3
Uprość swój dokument za pomocą odpowiedniego < doctype >
Jeśli istnieje emblemat reprezentujący prostotę HTML5 w świecie znaczników, jest to znacznik < DOCTYPE >. Znacznik < doctype > HTML5 jest łatwy w użyciu. Kiedy otwierasz dokument XHTML, pierwszą rzeczą, którą widzisz, pierwszą linią dokumentu, jest bałagan:
< ! DOCTYPE html PUBLIC "- // W3C // DTD XHTML 1.0 Transitional // EN" http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd >
Znacznik < DOCTYPE > przeszłość HTML, odziedziczony z podstaw SGML, składał się z trzech głównych składników: nazwy znacznika, publicznego ciągu identyfikującego i adresu URL DTD (Definicja typu dokumentu). Jest to dziwna mieszanka wielkich i małych liter, znaków cudzysłowu i ukośników oraz adresu URL, który wyświetla jeszcze mniej czytelny plik. Aby uczynić go jeszcze dziwniejszym, znacznik < DOCTYPE > jest unikalny, ponieważ jest jedynym znacznikiem HTML od HTML 4.01, który jest pisany wielkimi literami. HTML5 żegna się z tym wszystkim i upraszcza:
< ! doctype html >
Przeglądarka używa < doctype >, aby wiedzieć, jak renderować stronę internetową. Większość przeglądarek nie pobierała DTD z adresu URL, ale zmieniły swoje zachowanie na podstawie < DOCTYPE >. Jeśli przeglądarka napotka poprzedni kod, przełączy się do trybu standardowego (w przeciwieństwie do trybu dziwactwa) i zastosuje formatowanie przejściowe XHTML. Biorąc to wszystko pod uwagę, w jaki sposób HTML5 może uniknąć podstawowego < doctype > takiego jak html? Prosta odpowiedź jest taka, że nowy < doctype > jest "prostą odpowiedzią". Nowy < doctype > został stworzony, aby uruchomić uproszczone podejście do renderowania dokumentów, a nie spełniać stare oczekiwania. Twórcy przeglądarek osiągnęli konsensus co do sposobu obsługiwania funkcji specyficznych dla przeglądarki, więc nie ma potrzeby renderowania strony w "trybie dziwactwa". Jeśli wszystkie przeglądarki wyświetlają się w standardowy sposób, DTD nie jest konieczne; dlatego prosta deklaracja html stwierdza, że przeglądarka powinna odłożyć dowolny DTD i po prostu renderować stronę. HTML5 to uproszczona wersja HTML. Znaczniki są mniej złożone, funkcje są mniej złożone, a co najważniejsze, reguły są mniej złożone. Jednak w większości pisanych aplikacji nie będziesz jeszcze obsługiwał bazy użytkowników, która konsekwentnie obsługuje HTML5. Jak więc przełączać się między < doctype > s, gdy < doctype > ma być pierwszym wierszem dokumentu? To nie pozostawia wiele miejsca na sztuczki JavaScript lub fantazyjne hacki. Cóż, dobre wieści; istnieje również < doctype > HTML5 kompatybilny wstecz:
< ! DOCTYPE html >
"Ale czekaj" - mówisz. "Czy to nie ten sam prosty < doctype > przedstawiony wcześniej?" Tak to jest! Jedyną kluczową różnicą jest to, że "doctype" jest teraz pisane wielkimi literami. W specyfikacji HTML5 podano, że < doctype > nie rozróżnia wielkości liter; jednak poprzednie wersje HTML wymagały wielkiej litery < doctype >. Przekonasz się, że znaczna część HTML5 jest wstecznie kompatybilna z wcześniejszymi wersjami. Zdecydowana większość dostępnych obecnie na rynku przeglądarek zobaczy nowy < doctype > i rozpozna go jako "tryb standardowy" do renderowania stron.
Korzystanie z wersji < doctype > kompatybilnej z poprzednimi wersjami pozwoli ci dziś zacząć korzystać z HTML5, jednocześnie obsługując przeglądarki z przeszłości!
HACK No.4
Przyjęcie wspólnych struktur
Wiele dokumentów internetowych ma podobną strukturę. Skorzystaj ze znaczników, które ułatwiają dzielenie się stylami i oczekiwaniami. Projektanci i programiści stron internetowych od dawna dostosowują się do komponentów strukturalnych na stronie. Wspólna struktura strony wysokiego poziomu może wyglądać mniej więcej tak:
< ! DOCTYPE html PUBLIC "- // W3C // DTD XHTML 1.0 Transitional // EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd" >
< html >
< head >
< meta http-equiv = "content-type" content = "text / html; charset = UTF-8" / >
< title > … < /title >
< /head >
< body >
< div id = "header" > ... < /div >
< div id = "nav"> ... < /div >
< div id = "article" > ... < /div >
< div id = "footer" > ... < /div >
< /body >
< /html >
Zwróć uwagę na "strukturalne" identyfikatory na stronie. Odzwierciedla to dobrze zorganizowaną zawartość i przejrzystą strukturę strony. Problem z poprzednim kodem polega na tym, że prawie każdy element znaczników jest div. Dzielniki są świetne, ale przydają się w definicji strony bez kojarzenia ich z identyfikatorem. Problem z używaniem identyfikatorów do powiązania ról polega na tym, że gdy chcesz je wykorzystać do innego celu - powiedzmy, aby zidentyfikować drzewo dokumentów - napotykasz problemy: jak tylko dodasz narzędzie takie jak YUI Grids lub WordPress do strony, która faktycznie używa identyfikatora div, jest w konflikcie z twoimi "rolami div", a następną rzeczą, o której wiesz, że dodajesz warstwy div, aby zaspokoić swoje potrzeby strukturalne. W rezultacie pokazana wcześniej czysta strona może teraz wyglądać mniej więcej tak:
< html >
< head >
< meta http-equiv = "content-type" content = "text / html; charset = UTF-8" / >
< title > … < /title >
< /head >
< body >
< div id = "header">
< div id = "nav" >
< div id = "doc2" >
< div id = "wordpress-org-2833893" > … < /div >
< /div >
< /div >
< div id = "article" >
< div id = "doc2" >
< div id = "wordpress-org-887478" > … < /div >
< /div >
< /div >
< div id = "footer" > … < /div >
< /body >
Dość szybko widać, gdzie robi się bałagan, ale nie chcemy porzucać idei elementów strukturalnych, które deklarują segmenty stron - wiele czytników kodów, takich jak czytniki ekranu i boty wyszukiwania, zaczęło polegać na konwencjach strukturalnych. Podobnie jak w przypadku wielu części HTML5, nowe tagi strukturalne zapewniają proste rozwiązanie problemu dodatkowej złożoności. Zbudujmy naszą stronę z elementami strukturalnymi:
< ! DOCTYPE html >
< html >
< head >
< meta charset = "UTF-8" >
< title > … < /title >
< /head >
< body >
< header > … < /header >
< nav > … < /nav >
< article > … < /article >
< footer > … < /footer >
< /body >
< /html >
Po raz kolejny mamy proste, czyste rozwiązanie HTML5, dzięki któremu nasza strona jest łatwa w obsłudze i łatwa w obsłudze przez czytniki ekranu i boty wyszukiwania. Ten sam kod może również zaspokoić potrzeby naszych produktów innych firm, jak pokazano w następującym rozwiązaniu:
< ! DOCTYPE html >
< html >
< head >
< meta charset = "UTF-8" >
< title > … < /title >
< /head >
< body >
< header data-yuigrid = "doc2" data-wordpress = "2833893" > …. < /header >
< nav > … < /nav >
< article data-yuigrid = "doc2" data-wordpress = "887478" > … < /article >
< footer > … < /footer >
< /body >
< /html >
Przejdziemy do atrybutów danych w dalszej części, ale na razie musisz zrozumieć, że to rozwiązanie pozwala zachować elementy strukturalne strony i pozwolić komponentom zewnętrznym stosować identyfikatory do węzłów, uwalniając się atrybuty id do kontrolowania przez autora strony.
Uwaga programisto zewnętrzny: nigdy nie zakładaj, że element id należy do ciebie!
Wszystko to i więcej
HTML5 nie zatrzymywał się na nowych tagach omówionych w poprzedniej sekcji. Oto częściowa lista niektórych nowych znaczników HTML5, na które warto zwrócić uwagę:
< article > < aside > < figcaption > < figure > < footer > < header > < hgroup > < mark > < nav > < section > < time > < keygen > < meter > < summary >
Wiele z tych tagów wyrosło z powszechnego użytku przez twórców stron internetowych. W3C sprytnie postanowił "utorować krowie ścieżki" zamiast próbować zmienić zachowanie programistów. W ten sposób tagi są ogólnie przydatne do natychmiastowego przyjęcia. W większości przypadków intencja każdego tagu jest dość oczywista. Znaczniki < header > i < footer > robią dokładnie to, co mówią: określają nagłówek i stopkę strony (lub aplikacji). Używasz < nav > do zawinięcia nawigacji. Znaczniki < section > i < article > dają opcje nadużytego znacznika < div >; użyj ich, aby podzielić stronę zgodnie z treścią (np. zawiń swoje artykuły w tag < article >). Znacznik < aside > działa w podobny sposób jak znacznik < article >, ale grupuje treść obok treści strony głównej. Znacznik < figure > odnosi się do samodzielnej treści i tak dalej. Pamiętaj, że ta lista nie jest rozstrzygająca i zawsze się zmienia
HACK No.5
Spraw, aby nowe tagi HTML5 renderowały się poprawnie w starszych przeglądarkach
Nie czekaj na pełne przyjęcie HTML5 w sieci. Spraw, aby tagi strukturalne HTML5 wyświetlały się poprawnie we wszystkich przeglądarkach. Tak więc teraz masz cały nowy świat elementów HTML5, który pozwoli ci być zarówno ekspresyjnym, jak i semantycznym dzięki znacznikom. Uwolniono Cię od kajdan div i znów możesz pokazać swoją twarz na przyjęciach!
UWAGA: Znaczniki semantyczne to znaczące użycie znaczników. Rozdzielenie struktury i prezentacji prowadzi nas do zdefiniowania naszej prezentacji (wyglądu i działania) za pomocą CSS, a nasza treść za pomocą znaczących lub semantycznych znaczników.
Czujesz się dobrze, dopóki nie przypomnisz sobie, że niektórzy użytkownicy nie używają przeglądarek HTML5, a ponieważ jesteś elitarnym standardem sieciowym, twoja strona musi być kompatybilna wstecz. Nie wyrzucaj jeszcze tych tagów HTML5 przez okno. Ten hack nauczy Cię, jak napisać kod raz i używać go we wszystkich przeglądarkach. Każda przeglądarka wykonana w ciągu ostatnich 10 lat będzie widzieć tagi HTML5 na jeden z 3 sposobów:
1. Zobacz znacznik HTML5 i odpowiednio go renderuj (gratulacje, wspierasz HTML5!).
2. Zobacz znacznik HTML5, nie rozpoznawaj go i uznaj go za niestylizowany (domyślnie wbudowany) element DOM (Document Object Model).
3. Zobacz znacznik HTML5, nie rozpoznawaj go i całkowicie go zignoruj, budując DOM bez niego.
Opcja 1 jest prosta: używasz przeglądarki HTML5. Opcja 2 jest również dość łatwa do rozwiązania, ponieważ wystarczy ustawić domyślne parametry wyświetlania w CSS. Należy pamiętać, że w przypadku opcji 2 nie masz funkcjonalnych interfejsów API DOM dla tych nowych tagów, więc nie jest to prawdziwa obsługa tagów. Innymi słowy, użycie tej metody do utworzenia elementu licznika nie tworzy funkcjonalnego licznika. W naszym przypadku użycia znaczników semantycznych nie powinno to jednak stanowić problemu.
Skupiając się na opcji 3, używasz IE 6, 7 lub 8 i ładujesz stronę zawierającą nowe znaczniki semantyczne HTML5. Kod będzie wyglądał mniej więcej tak:
< !DOCTYPE html >
< html >
< head >
< meta charset="UTF-8" >
< title >My New Page with Nav< /title >
< /head >
< body >
< div >
< nav class="nav" >
< p >this is nav text< /p >
< /nav >
< /div >
< /body >
< /html >
Istnieją zasadniczo dwa różne sposoby radzenia sobie z tym brakiem wsparcia.
Plan awaryjny div
W poprzednim przykładzie kodu element nav nie jest rozpoznawany i jest przekazywany w czasie renderowania. Ponieważ DOM nie rozpoznaje tych elementów, opcja 1 wykorzystuje element zastępczy, który rozpoznaje przeglądarka, i otacza w nim każdy nierozpoznany element. Poniższy kod powinien ułatwić zrozumienie:
< !DOCTYPE html >
< html >
< head >
< meta charset="UTF-8" >
< title >My New Page with Nav< /title >
< /head >
< body >
< div >
< nav class="nav" >
< div class="nav-div" >
< p >this is nav text< /p >
< /div >
< /nav >
< /div >
< /body >
< /html >
Voil?! Możemy teraz stylizować element klasą nav-div zamiast elementu klasą nav, a nasz DOM będzie kompletny we wszystkich popularnych przeglądarkach. Nasza strona będzie poprawnie stylizowana i będziemy mieć nowe tagi HTML5 dla czytników ekranu i wyszukiwarek, które skorzystają z tagów semantycznych. Ta metoda będzie działać, ale istnieją pewne wady tego rozwiązania. Po pierwsze, posiadanie duplikatów tagów neguje korzyści na wiele sposobów, ponieważ nadal używamy div dla każdego strukturalnego elementu strony. Największym problemem tego rozwiązania jest jednak to, w jaki sposób psuje ono drzewo DOM. Nie mamy już
spójna relacja rodzic-dziecko od przeglądarki do przeglądarki. Przeglądarki, które rozpoznają element HTML5, będą miały dodatkowy "element nadrzędny" względem zawartości elementu, więc drzewa będą się różnić w zależności od przeglądarki. Możesz myśleć, że nie musisz się tym przejmować, ale jak tylko zaczniesz uzyskiwać dostęp do DOM za pomocą JavaScript (zwłaszcza jeśli korzystasz z biblioteki JavaScript, takiej jak YUI lub jQuery), napotkasz problemy z przeglądarkami.
Prawdziwy hack DOM: HTML5 Shim (lub Shiv)
Z przyjemnością informuję, że jest drugie i moim zdaniem lepsze rozwiązanie naszego problemu. Wierzę, że ta "funkcja" została odkryta przez Sjoerda Visschera w 2002 roku, kiedy przeszedł z createElement na innerHTML i zdał sobie sprawę, że stracił umiejętność stylizowania nierozpoznanych elementów. Przewiń do 2008 roku, kiedy John Resic zdał sobie sprawę, że może wykorzystać ten sam błąd, aby elementy HTML5 były rozpoznawalne w IE; nazwał tę funkcję "shiv HTML5", chociaż technicznie jest to sztuczka. Oto szczegóły. Stare wersje IE nie rozpoznają elementów HTML5 w sposób naturalny, ale gdy tylko użyjesz document.createElement () w nagłówku dokumentu przekazującego nierozpoznany element, IE doda element do swojej biblioteki znaczników i można go stylizować za pomocą CSS. Wróćmy do znaczników:
< !DOCTYPE html >
< html >
< head >
< meta charset="UTF-8" >
< title >My New Page with Nav< /title >
< style >
.nav {
color: red
}
nav {
display: block;
background-color: blue
}
< /style >
< /head >
< body >
< div >
< nav class="nav" >
< p >this is nav text< /p >
< /nav >
< /div >
< /body >
< /html >
Rysunek pokazuje efekt
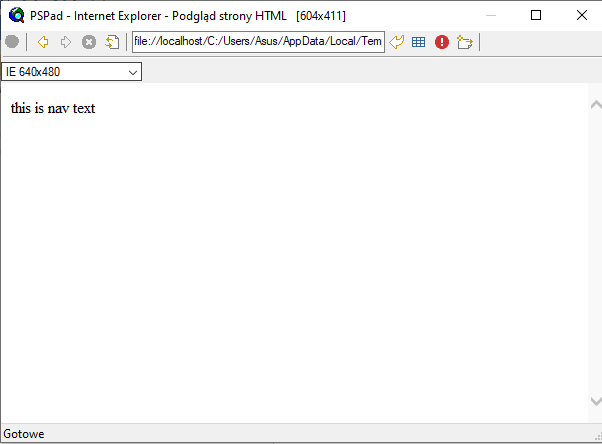
Zauważ, że element nie odebrał koloru z nazwy znacznika lub klasy CSS przypisanej do znacznika; po prostu to zignorował. Teraz wrzućmy nasz JavaScript i spróbujmy jeszcze raz:
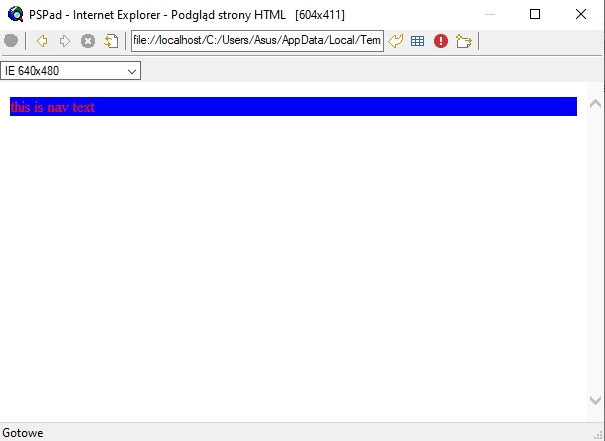
HACK No.6
Przywróć znacznik < input >
HTML5 tchnął nowe życie w znacznik < input >. Czas znów ekscytować się tym "odwiecznym" znacznikiem. Muszę przyznać, że trochę się nudziłem znacznikiem < input >. Przed HTML5 każda rzeczywista interakcja musiała być wykonywana poza znacznikiem: czy interakcja wymagała walidacji, formatowania lub prezentacji graficznej, JavaScript był niezbędnym wypełniaczem. HTML5 dał nam powód do ekscytacji znacznikiem < input >. Znacznik < input > sam w sobie nie jest tak naprawdę znacnznikiem HTML5. Jest to ten sam znacznik < input >, który mieliśmy w każdej poprzedniej wersji HTML, ale HTML5 dodał mnóstwo nowych funkcji. Dobrą rzeczą w aktualizowaniu istniejącego znaczniku jest jego naturalna zgodność z poprzednimi wersjami. Możesz zakodować swój znacznik w następujący sposób:
< input type = "date" / >
a przeglądarki inne niż HTML5 po prostu to zobaczą:
< input >
W tym hacku przyjrzymy się kilku nowym, wspólnym cechom tego cudownego znacznika
Niektóre podstawy
W znaczniku < input > HTML5 jest kilka podstawowych (ale potężnych) nowych funkcji, które są dostępne dla prawie każdego typu danych wejściowych. Zaczniemy od spojrzenia na niektóre proste atrybuty, a następnie przejdziemy do bardziej złożonych. Najpierw na liście jest placeholder, który jest łańcuchem przypisanym do atrybutu zastępczego, który zapewnia podpowiedź do pola wprowadzania. placeholder jest bardzo przydatny i szybko staje się powszechny. Tekst pojawia się, gdy wartość wejściowa jest pusta, i znika, gdy fokus zostanie ustawiony. Następnie pojawia się ponownie, gdy traci fokus (pod warunkiem, że pole wprowadzania danych jest nadal puste). Innym częstym atrybutem jest autofocus, który, jak można się domyślić po nazwie, przenosi fokus na element po załadowaniu dokumentu. Po prostu ustaw autofocus = "autofocus" (lub po prostu dodaj autofocus jako atrybut), a po załadowaniu strony będzie to domyślny element fokusa (w przeciwieństwie do skupiania się na pierwszym elemencie strony). Wymagany atrybut to
kolejny z tych wzorców, który został osiągnięty przez JavaScript od lat, ale w końcu wprowadził go do funkcjonalności DOM. Wystarczy dodać atrybut wymagany = "wymagany" (lub po prostu wymagany) do danych wejściowych, a DOM nie prześle formularza, gdy wymagania tego pola nie są spełnione. Spójrzmy na szybki przykład:
< !DOCTYPE html >
< html >
< body >
< form >
Add your telephone: < input type="tel" name="phone" required / >< br / >
< input type="submit" / >
< /form >
< /body >
< /html >
Jeśli spróbujesz nacisnąć przycisk Prześlij bez podania wartości w polu, przeglądarka wyświetli domyślną wiadomość w stylu "Proszę wypełnić to pole". To nie jest idealne, ale to początek. Atrybut formy to funkcja, która już dawno się pojawiła. Czy kiedykolwiek chciałeś mieć formularz na swojej stronie, ale bez ograniczania elementów formularza do jednej sekcji DOM? Być może korzystasz z urządzenia mobilnego i chciałbyś, aby przycisk Prześlij pojawiał się u dołu ekranu zamiast przebywać w obszarze formularza. Atrybut formularza pozwala utworzyć element formularza dla formularza, nawet jeśli nie jest on węzłem potomnym formularza. Po prostu ustaw atrybut formularza na identyfikator formularza (nie może to być nazwa formularza lub inny atrybut, coś, co W3C musi rozwiązać). W przypadku tego atrybutu powyższy przykład wyglądałby mniej więcej tak:
< !DOCTYPE html >
< html >
< body >
< form id="myForm" >
Add your telephone: < input type="tel" name="phone" required / >< br / >
< /form >
< input type="submit" form="myForm" / >
< /body >
< /html >
Teraz, gdy omówiliśmy podstawy znaczniku < input >, przejdźmy do niektórych ciekawszych funkcji znacznika
Atrybut autocomplete
Internet zdecydowanie fascynuje się autouzupełnianiem. Ponieważ wszyscy nie lubimy pisać, uwielbiamy go, gdy element formularza wie, co chcemy pisać, i robi to za nas. Tak więc pojawia się HTML5 i wprowadza autocomplet jako prosty atrybut. Ustawiasz autouzupełnianie na włączone lub wyłączone (domyślnie jest włączone) i praca jest zakończona! Kod wyglądałby mniej więcej tak:
< !DOCTYPE html >
< html >
< body >
< form id="myForm" >
Add your telephone: < input type="tel" name="phone" autocomplete="on"
/>< br / >
< /form >
< input type="submit" form="myForm" / >